
Windows上的内存清理软件,这就是个伪命题。
Android手机,要清理内存,把切到后台的应用干掉,就一键清理了。Windows上,你把一个缩小化(也没切到后台这概念)的程序(进程)杀掉试试,那就真的杀掉了。真要这么干你自己打开任务管理器就可以干了。
这种‘清理’是整个进程范围的,进程的全部内存空间都干掉了,之前所分配(映射)的物理内存页(working set)会被放到一个free list以供他人使用。如果是用来map文件内容的物理页(通常称为cache)则放到standby list,仍然可以起到cache作用。
那么如何不杀掉一个进程去“清理”它的内存?你试试直接remote spawn一个thread然后VirtualFree,那画面就太美了。
唯一能做的可能就是缩小该进程的working set。所谓working set是指还进程分配的虚拟内存中(注意Windows程序大部分时候申请的都是所谓虚拟内存)真正映射在物理内存的大小,没在这里面的就是暂时写到pagefile了。缩小working set其实就是把更多的放在物理内存页上的内容写到pagefile以释放这页物理内存。
这个确实可以通过SetProcessWorkingSetSize来实现,但是请注意随便减小一个正在运行的进程的workingset,是一件非常坑爹的事情。脑补一下某进程刚申请了一块内存,放了点数据进去,还没用完就被“清理”,写到pagefile。但是当该进程又去访问还地址空间时,这块内容又会从pagefile中被读回来。无缘无故多了两次disk io。当然实际情况比较复杂,这里只是简化了。
那么进程的working set大小究竟应该由谁来管理?显然大部分情况操作系统能更好得替你管理,真没必要操这个心。
系统怎么管理?首先你得理解,物理内存放着不用,那是犯罪。尽可能高效的利用每一页内存才是正道。Windows有三层空闲内存体系。第一层叫zero page list,里面的内存页都是填零的,当有内存需求的时候立刻就能用。第二层叫free list,如果有用户态内存需求则需要先清零变成zero page再分配。第三层叫standby list,通俗理解就是file cache(只是read的),如果前面两层都不够了就会从这里拿,自然也就扔掉了一些file cache。
这三层体系基本保证了新的内存需求能尽快得到满足。普通情况一个进程VirtualFree了一块内存,本来用到的物理页就会直接放到free list,根本不存在一个清理过程。然后会有一些zero page threads专门负责清零工作。而standby list也就是真file cache一般都很大,所以不大可能会发生新的请求会满足不了。
好了什么时候系统会做所谓内存清理?很明显如果3层list都光了那肯定要清理。另一种情况,当他发展最近的物理内存请求比较多的需要由standby list来完成,而不是前两层,那意味着file cache被循环丢得厉害,也会做一次清理。
怎么清理,其实就是走一边进程表然后减小大家的working set重新洗牌。这也是最后一招没办法的办法,diskio太多了。其实大部分时候是不会走到这一步的。zero/free/standby list多数都会被控制在比较健康的水准而不会发生强行清理。
Windows核心从nt开始发展了这么多年才到了今天的水平,memory management这块核心代码估计地球上只有不到5个人敢动,现在这块的掌门人已经是tech fellow级别了。外面所谓什么什么“一键优化”真是很可笑的。
作为轻度百度网盘使用者,实在是不喜欢他们推出的丰富的功能,比如,默认在我的电脑里加入百度网盘图标,强迫症晚期患者实在是不能忍。
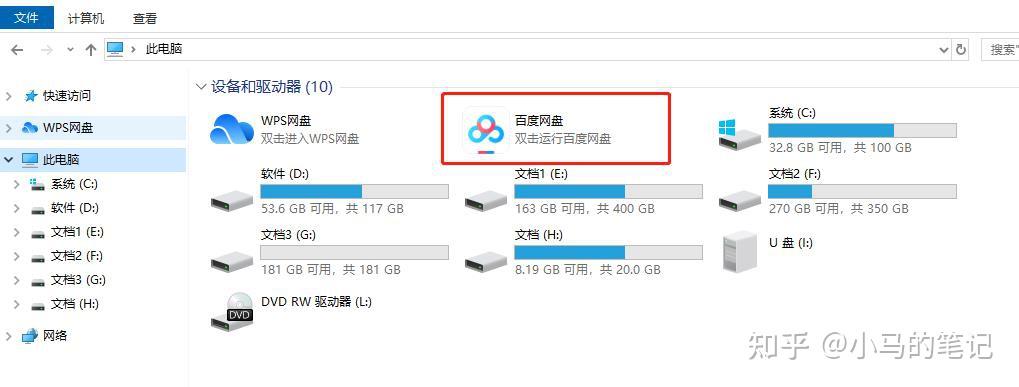
下面我们看看怎么将这图标隐藏。
第一种方法,打开百度网盘,点击百度网盘右上角的“设置”图标,选择“设置”,
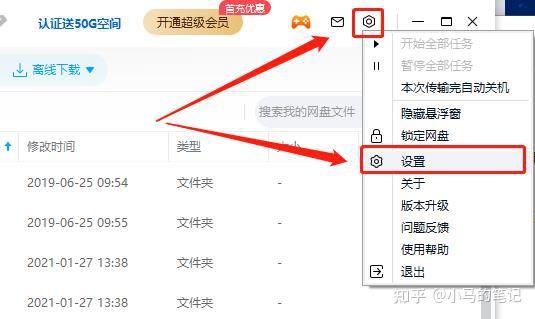
在弹出的“设置-基本”界面中将“在我的电脑中显示百度网盘”前面的勾取消,
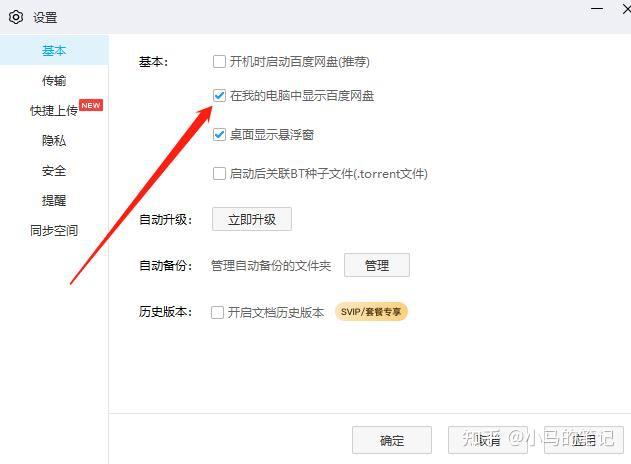
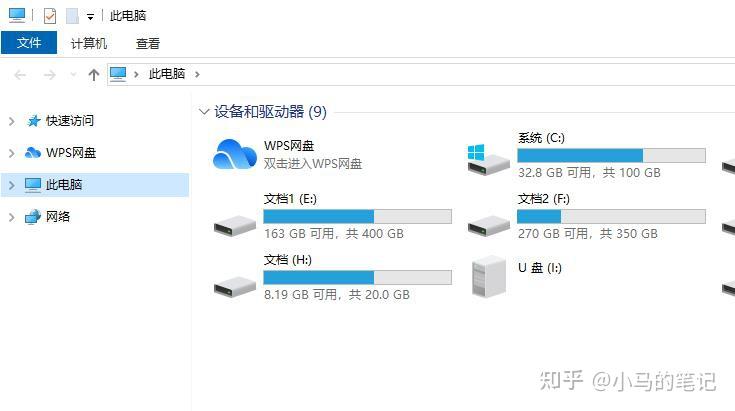
然后点击确定,然后回到“我的电脑”界面,刷新一下,就可以看到“百度网盘”图标已消失。
第二种方法,直接删除该注册表项。
(并不推荐此方法,因为百度网盘会一直修复此项,除非你再也不打开百度网盘)
win7系统下,点击开始-运行,输入regedit打开注册表;win10系统下,点击开始,直接输入regedit即可打开注册表;或者使用快捷按键win+R打开运行对话框,输入regedit打开注册表。
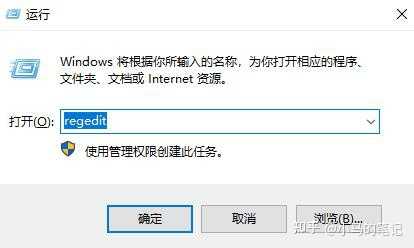
依次展开下述注册表菜单:HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Explorer\\MyComputer\\NameSpace,win10系统下可直接将“计算机\\HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Explorer\\MyComputer\\NameSpace”路径复制到注册表地址栏,按回车即可快速到达,
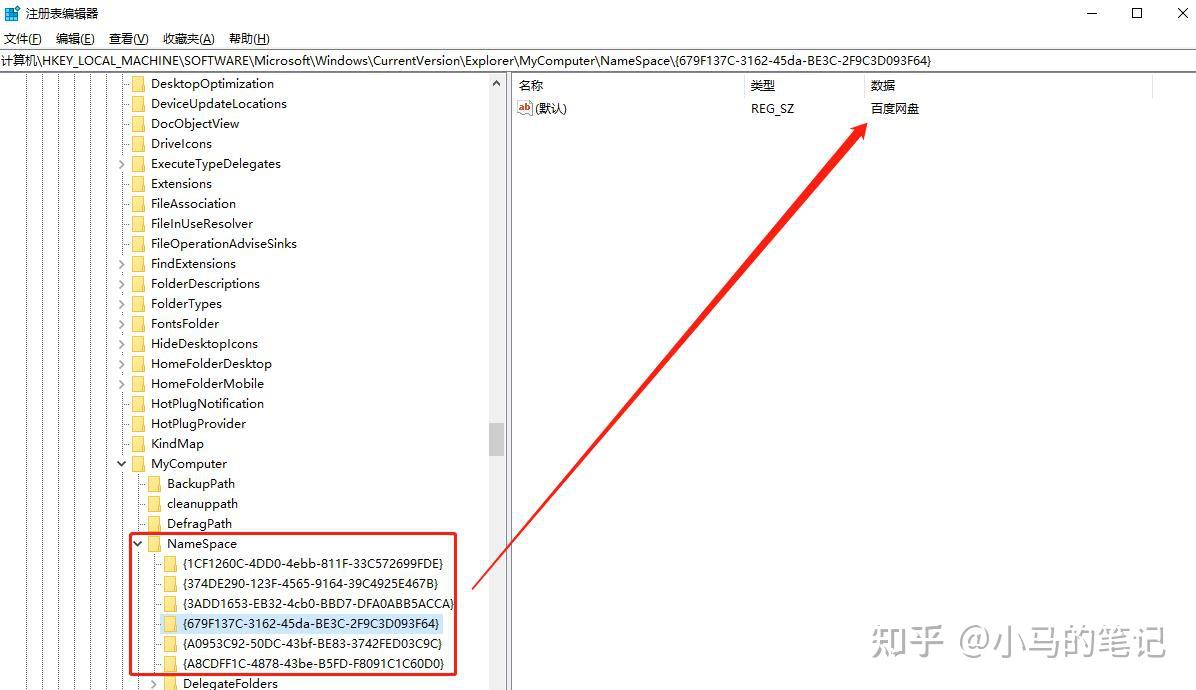
我们依次点击NameSpace下的各项,并关注右侧,找到含有“百度网盘”的这一项,然后直接删掉即可。
删除之后,
继续展开HKEY_CURRENT_USER\\Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\MyComputer\\NameSpace,同样win10系统下可直接将“计算机\\HKEY_CURRENT_USER\\Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\MyComputer\\NameSpace”路径复制到注册表地址栏,按回车即可快速到达,
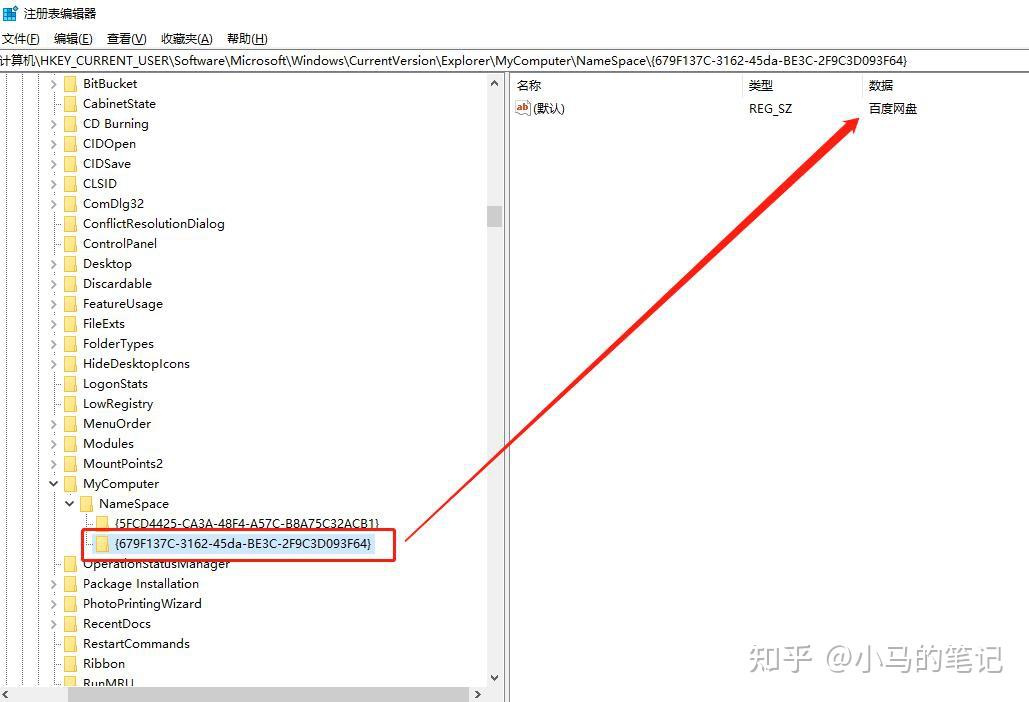
我们依次点击NameSpace下的各项,并关注右侧,找到含有“百度网盘”的这一项,然后直接删掉即可。
删除之后,回到“我的电脑”界面,刷新一下,就可以看到“百度网盘”图标已消失。
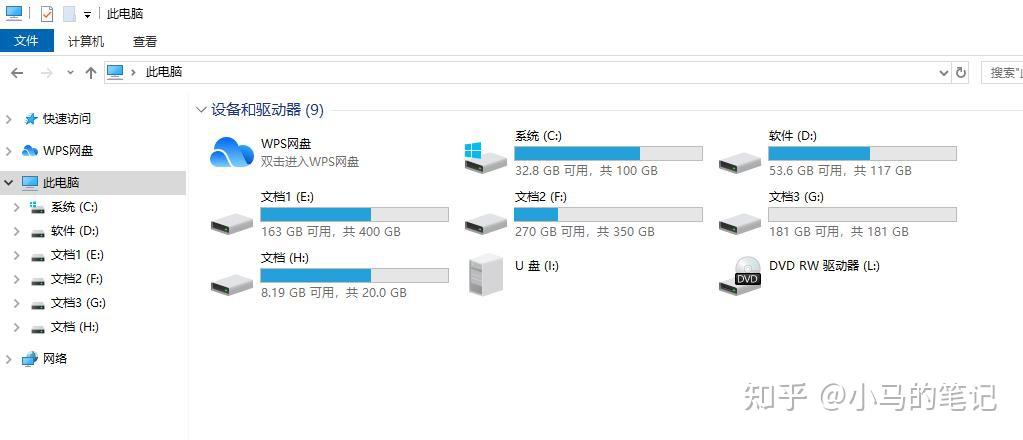
第二种方法的快捷方式,新建一个txt文本文档,将下面的内容复制到文本文档中,
Windows Registry Editor Version 5.00
[-HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Explorer\\MyComputer\\NameSpace\\{679F137C-3162-45da-BE3C-2F9C3D093F64}]
@="百度网盘"
[-HKEY_CURRENT_USER\\Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\MyComputer\\NameSpace\\{679F137C-3162-45da-BE3C-2F9C3D093F64}]
@="百度网盘"
保存后,修改该文本文档后缀名为.reg,

然后,双击,按提示点击“是”即可。出现下图提示,代表修改成功,
回到“我的电脑”界面,刷新一下,就可以看到“百度网盘”图标已消失。
PS:并不推荐第二种方法,因为百度网盘会一直修复此项,除非你再也不打开百度网盘,只要你打开百度网盘,在“设置-基本”界面中“在我的电脑中显示百度网盘”前面的勾没有取消,他会自动修复注册表项,我的电脑会立马再次出现百度网盘图标!!!

只要是普通的桌面应用(*.exe),就有权读写你帐户有权限的所有对象。包括但不限于你的个人文件、连接的网络位置、注册表、系统设置等。
如果有管理员权限,就更恐怖了。
而 Windows 可以通过设置注册表来达到这种效果。
希望 Windows 能对普通 *.exe 应用上沙盒隔离机制。
美团酒店直连项目自2013年末开始,通过业务上的不断完善和技术上的不断改进,至今已经接入200多家供应商,其中在线酒店3万以上,在线SPU30万以上。经过两年的成长,美团酒店直连平台终于在2015年末发展为国内最大的酒店直连业务平台,其接入的业务类型也从最初的经济连锁,拓展到高星渠道、小连锁集团、非标准住宿等,获得了业界一致好评。
随着美团点评的日益壮大,客户的需求和系统体量的不断增加,直连平台的技术架构和数据应用面临着诸多挑战。为了保障美团点评的用户体验度,对技术方面会提出更高的要求。
- 如何在合作方接口极不稳定的情况下保持高可用效果?
- 如何在不影响系统稳定性的前提下提升接口响应时间?
- 如何解决庞大数据带来的一致性问题的同时降低系统运营风险?
这些是直连平台每天都在思考的问题。技术平台和数据应用的改进完善并非一蹴而就。考虑到数据是业务运营的核心,这里先以产品数据一致性问题的解决方案作为切入点与大家分享,也希望借此抛砖引玉,欢迎更多的同学一起探讨,共同进步。
为了使数据一致性完善方案更直观易懂,这里引用美团酒店直连项目中直连平台与供应商酒店产品数据一致性方案作为分析案例,通过面临问题、总体思路、解决方案和总结思考四个方面进行论述。
酒店直连系统的主要工作是将供应商的酒店产品(房型),通过系统对接的方式,转化为美大点评平台可以售卖的产品(房型)。
酒店产品购买是一个可预订日期跨度比较长的业务。以美团App为例,可以预订60天内的酒店。
因此我们的系统需要将供应商全部酒店全部房型信息以及60天内的价格、库存、售卖取消规则等信息,获取到我方,落地后形成产品数据,一则用在C端给用户进行展示,二则参与交易环节。
下图为产品供给流向图: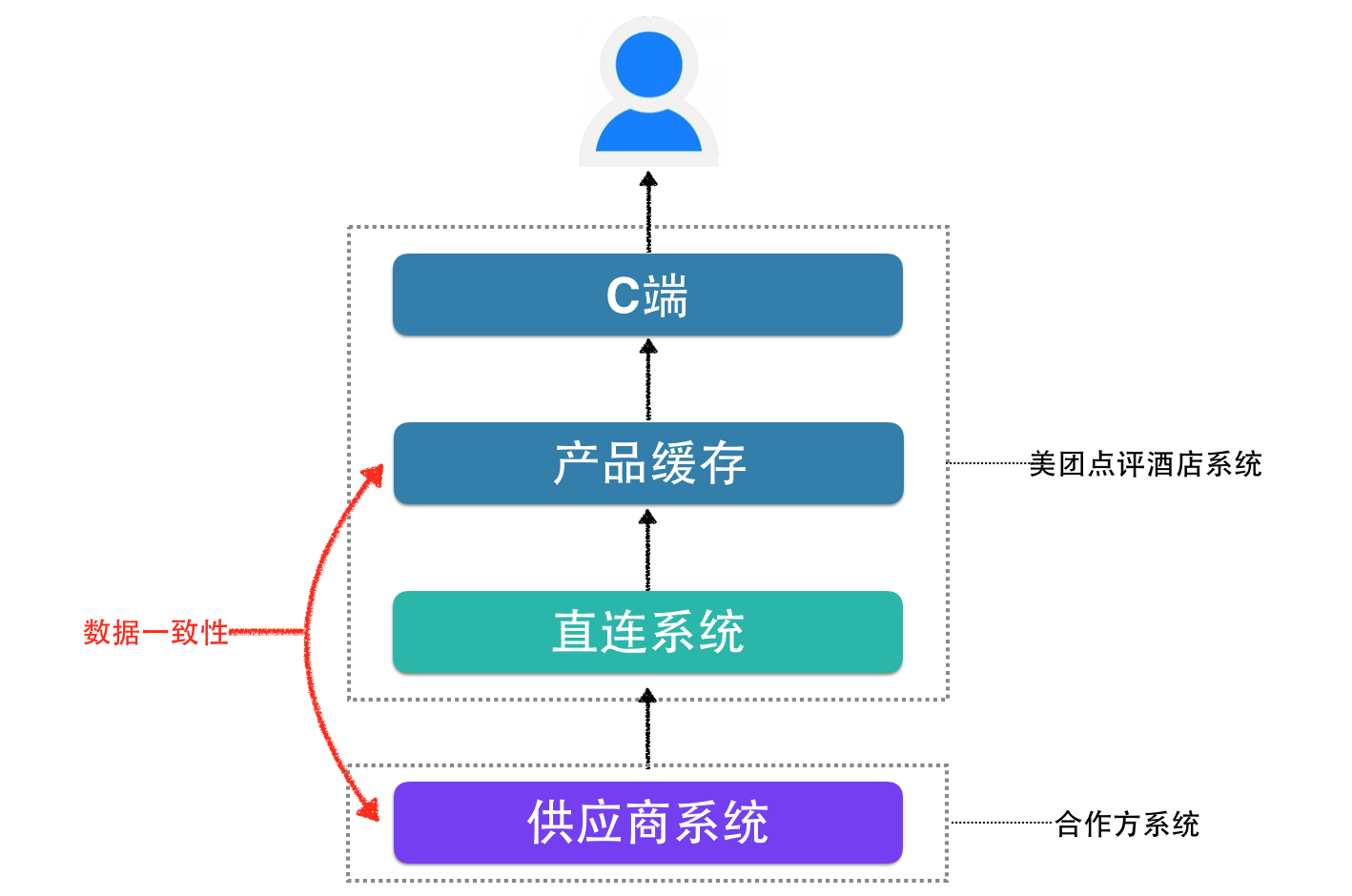
问题:直连系统在上单流程中如何保证产品缓存与供应商系统的数据一致性?
上述面临的情况很像数据库的主从同步问题,那我们是不是可以借鉴主从同步的方式来解决该问题呢?我们来看一下MySQL主从备份的实现细节:
MySQL使用3个线程来执行复制功能(其中1个在主服务器上,另2个在从服务器上)。当开始同步时,从服务器开始创建一个I/O线程,以连接主服务器,并且让主服务器发送在其二进制日志中的语句。主服务器创建一个线程将二进制日志中的内容发送到从服务器。 该线程即为主服务器上show processlist输出中的Binlog Dump线程。从服务器I/O线程读取主服务器Binlog Dump线程发送的内容,并将该数据复制到从服务器数据目录中的本地文件(即中继日志)中。 第3个线程是SQL线程,由从服务器创建,用于读取中继日志并执行日志中包含的更新。 在从服务器上,读取和执行更新语句被分成两个独立的任务。当从服务器启动时,其I/O线程可以很快地从主服务器索取所有二进制日志内容。
如下图: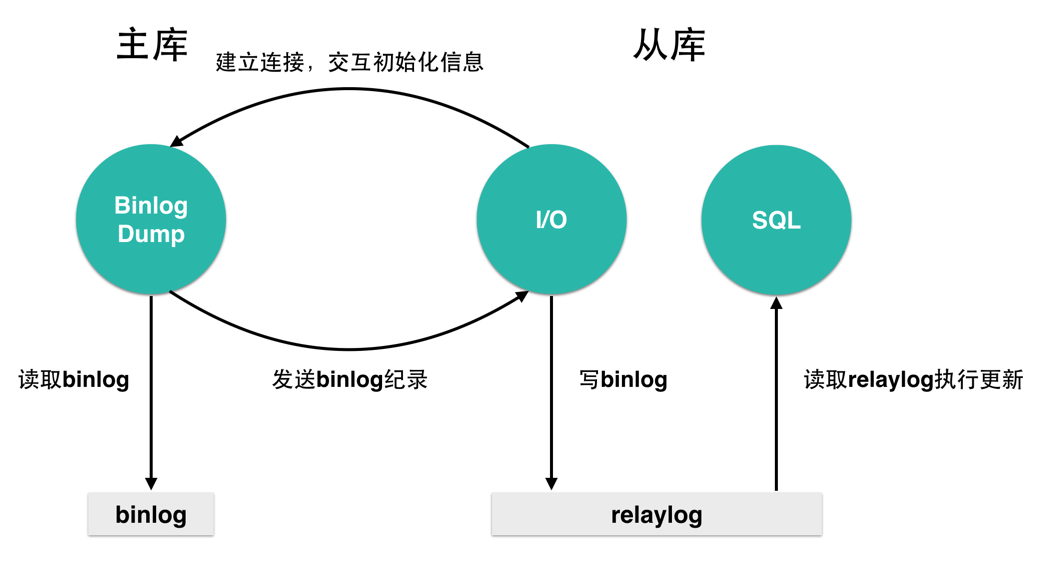
以上的数据同步方案广泛的运用在数据库的数据一致性问题上,而这也正是我们长久以来一直寻求的解决之道。
具体对应到我们的系统,美团直连平台和供应商的关系为:在供应商数据产生变化的时候,将变化的部分推送至直连平台。
听上去这是个很不错的方式,但这只是个美好的目标。诸多摆在我们面前的问题无法忽略:供应商的支持力度低、供应商网络稳定性差、供应商系统可用性差。
大思路有了,但是还有很多具体问题,接下来我们就来说说是怎么解决的。
直连产品数据一致性的演进大致可以分为四个阶段,按照落实的时间顺序具体的解决方案是:
- 从无到有:没有数据全量拉取
- 分而治之:数据太多分段拉取
- 精益求精:热门数据分析拉取
- 合作共赢:数据变化主动推送
前期合作的供应商经济连锁集团大都有一个特点,他们会提供一套标准的API给有合作意向的OTA进行开发,供应商不会对API进行任何逻辑上的修改。
因此,初期我们选取的产品数据同步方案为:从无到有,定时拉取供应商全量产品数据。
应用前提:数据量级不大,数据传输效率高,拉取耗时可控。
方案优点:开发周期短,逻辑简单,串行拉取。
方案缺点:可持续性差,异常恢复成本高,对网络传输的带宽和本地存储容量要求高。
案例分析:直连平台每30分钟主动拉取供应商下的全部酒店下全部房型信息以及60天内的价格,库存,售卖取消规则等信息。
如下图: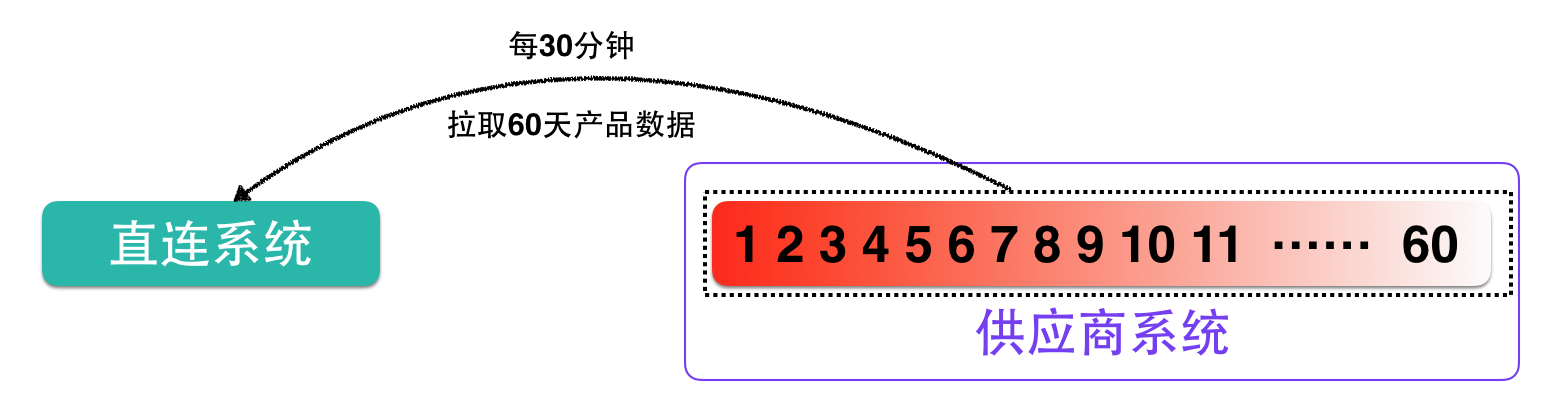
我们使用这个方案在同几家供应商进行合作了以后,陆续发现存在一些问题:
- 双方数据存在不一致性的时间跨度超过30分钟。
- 30分钟定时任务执行不完,出现任务重复调起的情况。
获取信息数据量庞大
假设一家中等规模的供应商有1000家酒店,每个酒店下面有10个房型。
获取信息数据量=1000(酒店)×10(房型)×60(天数)=60W
供应商接口速度很慢
供应商接口速度很慢 根据统计,供应商接口的平均响应时间在两三秒以上,获取产品接口由于数据量大,可能响应时间在几十秒甚至上百秒。
这时你可能会问:目前定时任务是每30分钟调起一次,缩短定时任务的调起时间就可以减少数据不一致问题的时间段呢?
这确实可以解决一部分问题,提前是任务在短时间就可以执行完成。但是对于长时间执行无法完成的任务可能适得其反,过于频繁的接口调用,反到把供应商的系统压垮了。
这是我们不愿意看到的,慢总比不能使用来得好些。
随着业务量的增大,数据不断激增,全量数据拉取的缺点将被不断放大,实效上无法保障业务对数据一致性的要求。此时,只有主动求变才能有效应对,这里我们采取的方案是:分而治之,结合实际分析拉取部分数据。
应用前提:充分调研,因地制宜,数据可分段获取。
方案优点:同步数据体量大幅降低,数据准确度有效提升。
方案缺点:还存在数据不一致的时间差。
案例分析:根据酒店的预订特点,调研了美团用户的消费习惯:95%以上的用户都在预订10天内的酒店产品。
我们将产品拉取方式调整了两种:
固定时间点(例:1点,7点,13点,20点)拉取全量60天的酒店产品数据。
每15分钟拉取10天的酒店产品数据(这就好比我们在查询数据库的时候添加了limit)。
同时调整拉取规则,拉取任务没有执行完成,不再重复调起,以减少对供应商系统的压力。
如下图: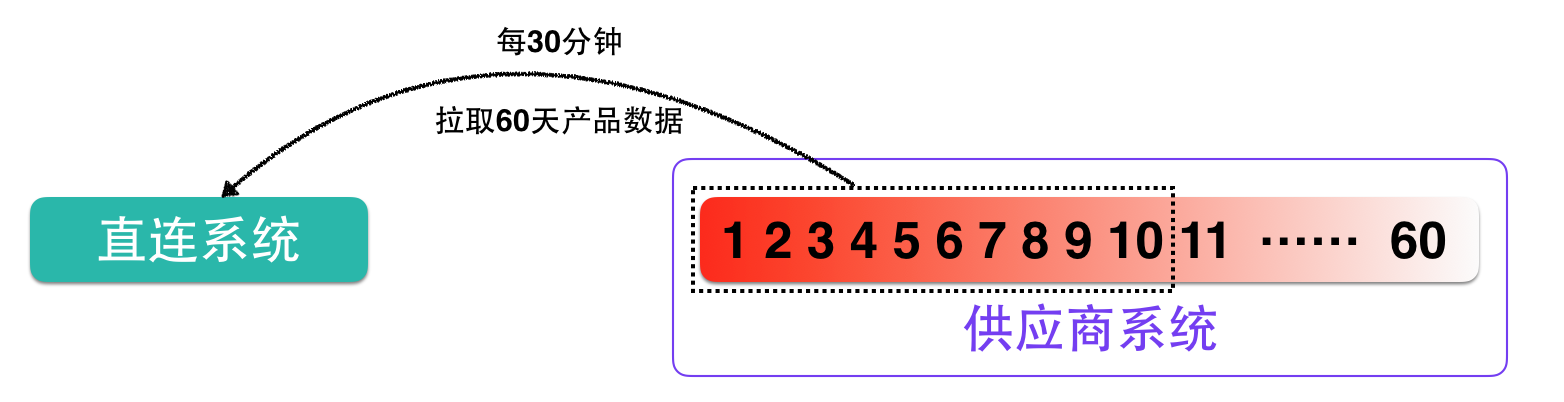
上述方案我们可以简单的认为将拉取的数据量和响应时间减少了近5/6,同时我们可以根据供应商的服务能力动态调整拉取频率,例如:2分钟可以执行完的任务,设置为每3分钟拉取一次。
即使因为网络抖动等原因引起的任务时间增加,也不用担心任务重复调起压垮供应商系统。
经过第二阶段,流程演进为:
综上,我们基本实现了不间断的拉取产品数据,同时是用户高频进行购买的产品,产品数据不一致性得大了很大幅度的缓解。
拉取部分产品数据的方案解决了绝大多数的产品数据不一致的问题,但是在2次拉取数据的间隔时间差内还会存在不一致的问题,会导致用户在支付之后没有预订到心仪的房型而自动退款,如选择退回原支付方账户,用户需要等待3~10个工作日,体验十分不好。
我们迫切需要改进该问题,提高用户体验。 对于“分而治之”方案的缺憾我们进一步思考,寻找到了解决的方案。
为了应对间隔时间差的问题,我们的解决的方案是:提前为用户准备热点数据。这个主要是靠触发式更新(被动)与库存预测(主动)来实现。
应用前提:摸清定位,准确匹配,对系统本身有深入的了解,同时对业务未来的发展趋势有一定的预测能力。
方案优点:数据准确度提高,降低数据一致性相关的资源消耗。
方案缺点:分析成本高,增加了分析数据捕获清洗的系统消耗。
案例分析:基于用户的访问行为情况,提前对产品进行数据更新,为用户准备好即将可能要购买的产品。
1. 基于用户下单行为更新数据
我们从预订流程入手,对原有的预订流程进行分析。
原有流程很简单,如下: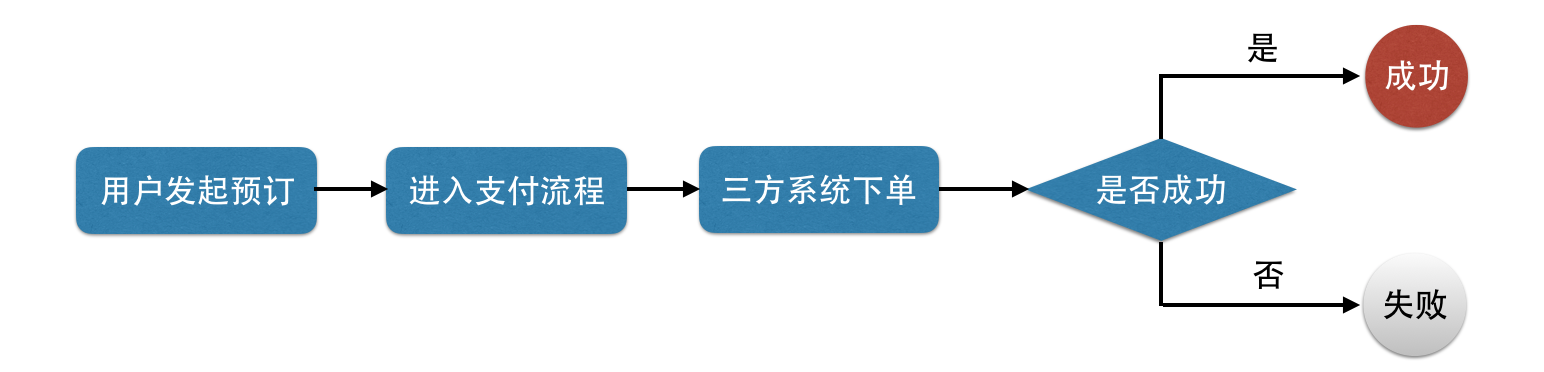
这其中最主要的问题是:用户下单时看到的产品是产品缓存,只是依据产品缓存就让用户进行了下单购买,这显然是不可靠的。
需要在用户下单的时候对产品的正确性进行验证。
针对这个问题,我们对下单流程进行优化,在用户进行支付前,添加下单前校验功能,对产品数据进行校验(价格,库存等)。
下单前校验的底层接口由供应商提供,要求实时校验产品数据,不能使用缓存数据。
经过我们的大力推动与行业的整体发展,供应商目前都意识到了该问题的重要性,基本都会提供相关接口以提升用户体验。
流程如下,绿色部分为新添加的下单前校验功能: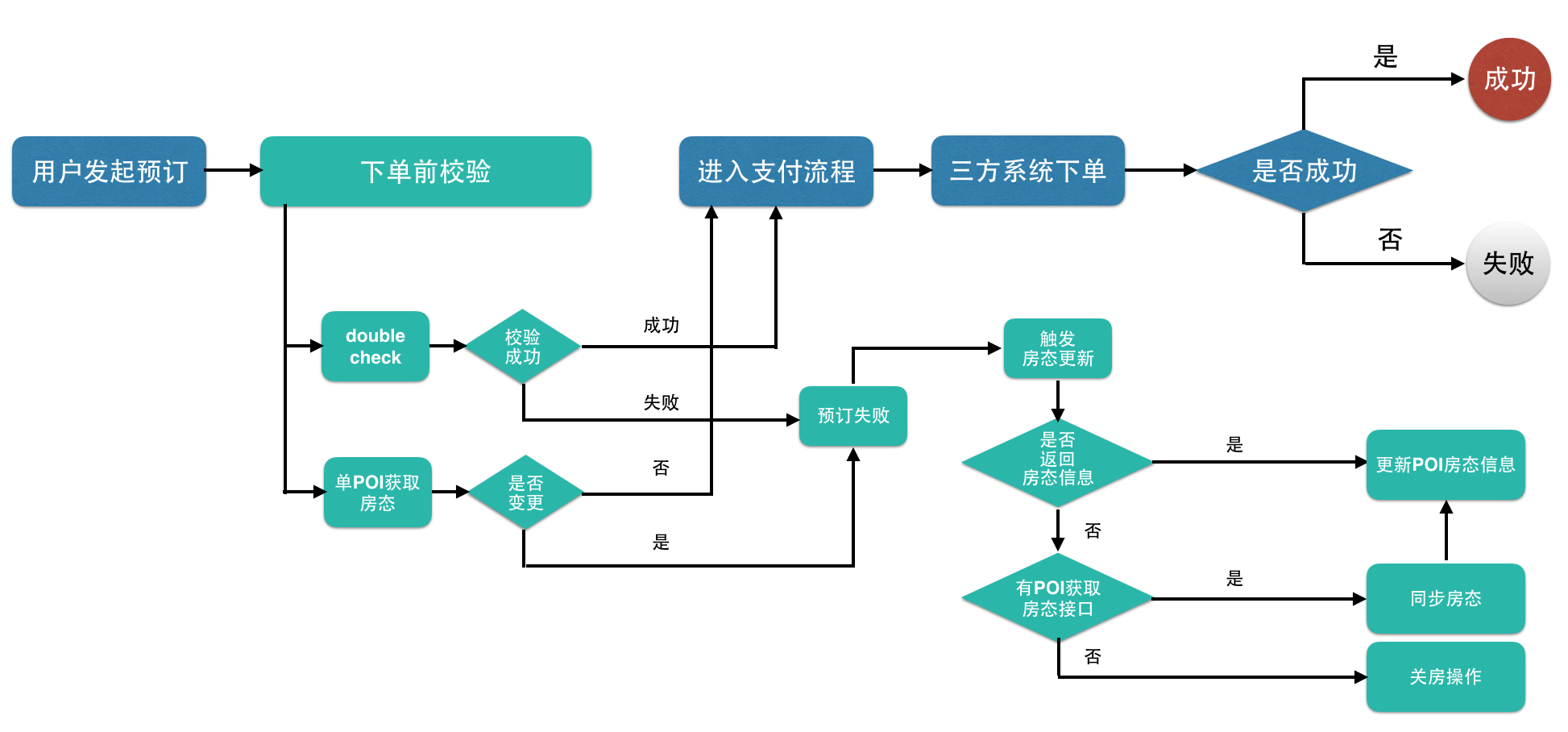
同时对于校验失败的产品会及时更新产品缓存,避免其他用户重复对失效产品进行反复下单。
在完成上述的改造之后,用户退款单量下降了一个数量级,由原来每天几千单下降到了几百单,用户体验大大提升。
那么为什么每天还会有几百单的退款?
用户下单前校验通过后,可能要过一段时间才会支付(支付等待时间,美团App为30分钟),恰巧在支付的过程中,产品库存不足或变价都会导致预订失败,在酒店的预订旺季问题会更加突出。
针对变价问题,可以优化流程告知用户,用户可以选择继续购买。
针对库存不足问题,可以为用户继续推荐其他产品。尽量满足用户需求。
以上问题不属于本文讨论范畴,故不再展开讨论。
流程演进为: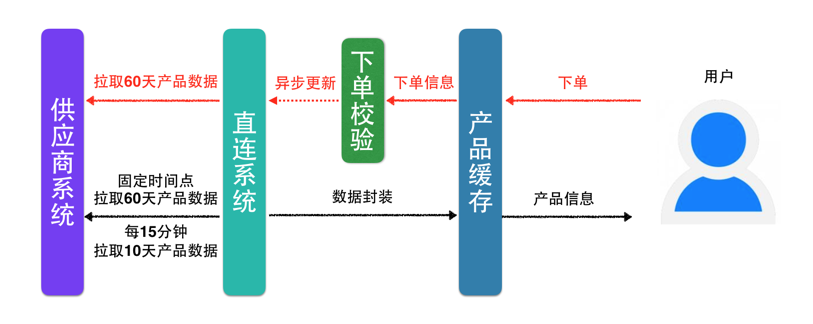
2. 基于用户浏览行为更新数据
基于用户下单行为更新数据,解决了“非第一个用户”重复下单的问题,但“第一个用户”被我们牺牲掉了。我们能否为“第一个用户”做些什么?或者说是如何减少“第一个用户”的存在?答案是肯定的。 在用户浏览页面的时候,异步通知直连系统,为用户提前准备可能购买产品的相关数据,如下图:
在这里有个策略问题:直连酒店详情页的浏览每天有几千万次,直连系统提供的异步接口QPS可以达到几百,过滤后的访问量也还是很大,将这些访问量全部转化成对于供应商系统的数据拉取,会导致供应商系统过载,甚至崩溃。这里我们针对每个不同的供应商设置一个“数据最小拉取时长”,小于该时长的访问,不再重复进行拉取,以减少供应商系统的访问次数。
例:P供应商,设置数据拉取时长为60秒。
A用户在10:00:00时访问H酒店的列表页,异步更新酒店产品数据。
B用户在10:00:59访问H酒店的列表页,不进行更新。
C用户在10:01:01访问H酒店的列表页,异步更新酒店产品数据。
流程演进为: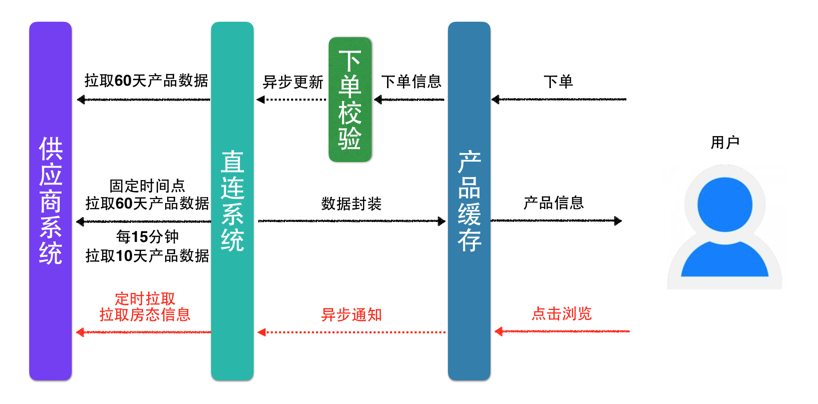
至此,我们已经解决了产品数据拉取的绝大多数问题,基本可以保证用户的正常购买。
谋求数据一致性提升必定带来系统成本的消耗,如何降低系统运行成本将是未来我们需要思考的方向。
数据的有效预测可以帮助我们很大程度上降低成本消耗。
仍以美团直连平台为例,触发式更新确实解决了“第一个用户”的问题,虽然我们使用了“数据最小拉取时长”的方案,但新增大量访问对供应商系统还是造成一定的压力。
如:P供应商,包含1000家酒店,数据最小拉取时长为:120秒。
访问量:1000(酒店数量)×30(每小时访问次数)×24(每天24小时)=720000
是不是有办法减少访问次数?同时尽量避免减少访问数次对用户的影响?答案也是肯定的。
我们抽象一下问题即为:在数据过载的前提下,及时为用户提供有意愿购买的产品信息。
那么什么是用户有意愿购买的产品呢?
可以简单的根据二八定律(20%的产品会给我们带来80%的收益),来维护这20%的头部产品数据,来达到我们的目的。
这20%的头部产品数据怎么获取?单纯的已浏览量和订单量,好像都不太正确。 回看一下问题中的关键词:数据过载,有意愿购买,产品信息,这些关键词都指向了一个明确的实现方案——推荐系统。
推荐系统常规的使用方式向用户推荐用户感兴趣的信息和商品。
我们这里对推荐系统进行灵活运用,当预测到用户对某些信息或商品感兴趣时,为用户提前准备好信息或商品数据。
推荐系统架构图: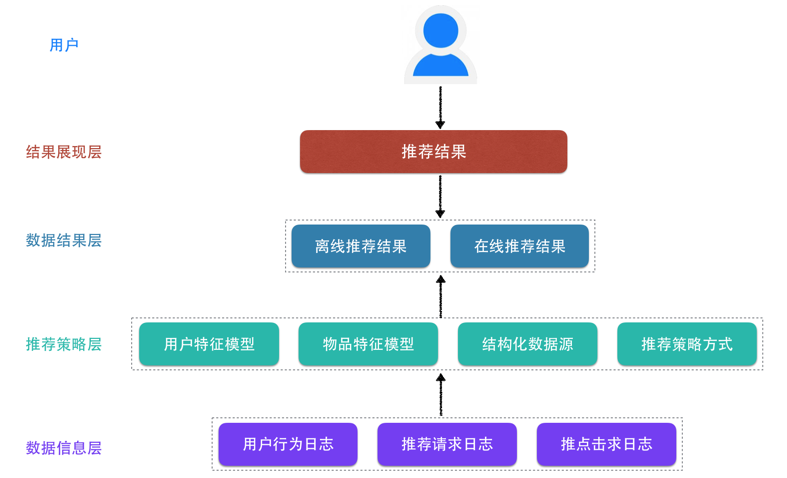
我们可以根据购买历史、价格区间、重点商圈、热销品牌等产品多维度信息,使用基于物品的协同过滤算法,区分出高中低频用户有意愿购买的产品,实现不同的数据拉取频率,以降低供应商接口的访问次数。
如果我们面临的属性维度极其复杂,要分析的数据量也十分巨大的时候,协同过滤算法可能就不适用了,这时可以考虑基于深度神经网络的推荐系统。
关于推荐系统这里不再展开讲述。
流程演进为: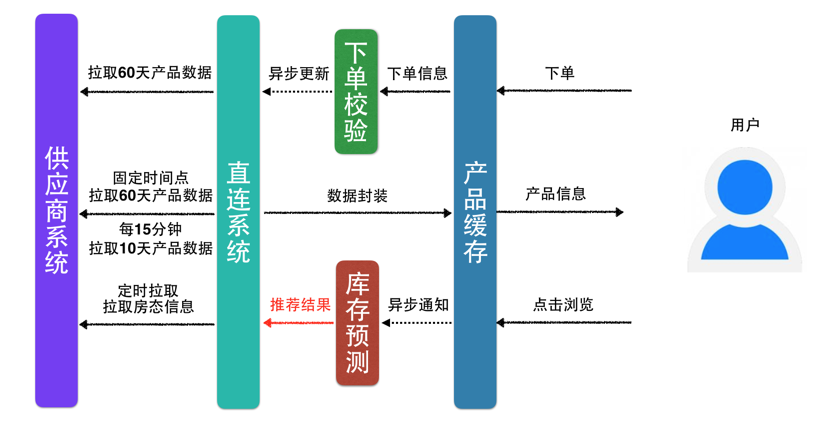
目前该方案我们还没有实现,但这是我们的发展方向。
虽然我们一直致力于完善我方系统提高数据一致性,但不可否认的是,最有效的手段还是谋求合作双方的合作,而这往往是个长期、艰苦卓绝、潜移默化的过程。虽然有着共同的目标,但由于工作量的增加对方往往并不积极配合,推动合作方系统的改进工作通常十分艰难。当然,这并不能阻止我们不断前进的步伐,我们在实践中逐渐摸索出一套方案,那就是:建立有效的沟通渠道+有力的技术支持。
应用前提:保持良好的沟通渠道,开发接口具备便利性和标准化。
方案优点:降低系统的访问次数,维护成本降低,数据准确度提升。
方案缺点:需要提供接入的标准API,同时沟通成本较高。
案例分析:在我们和供应商合作的过程中,经过我们的不断推动,供应商也意识到了,当数据发生变化时,主动推送数据给我们是最好的解决方案。
如图: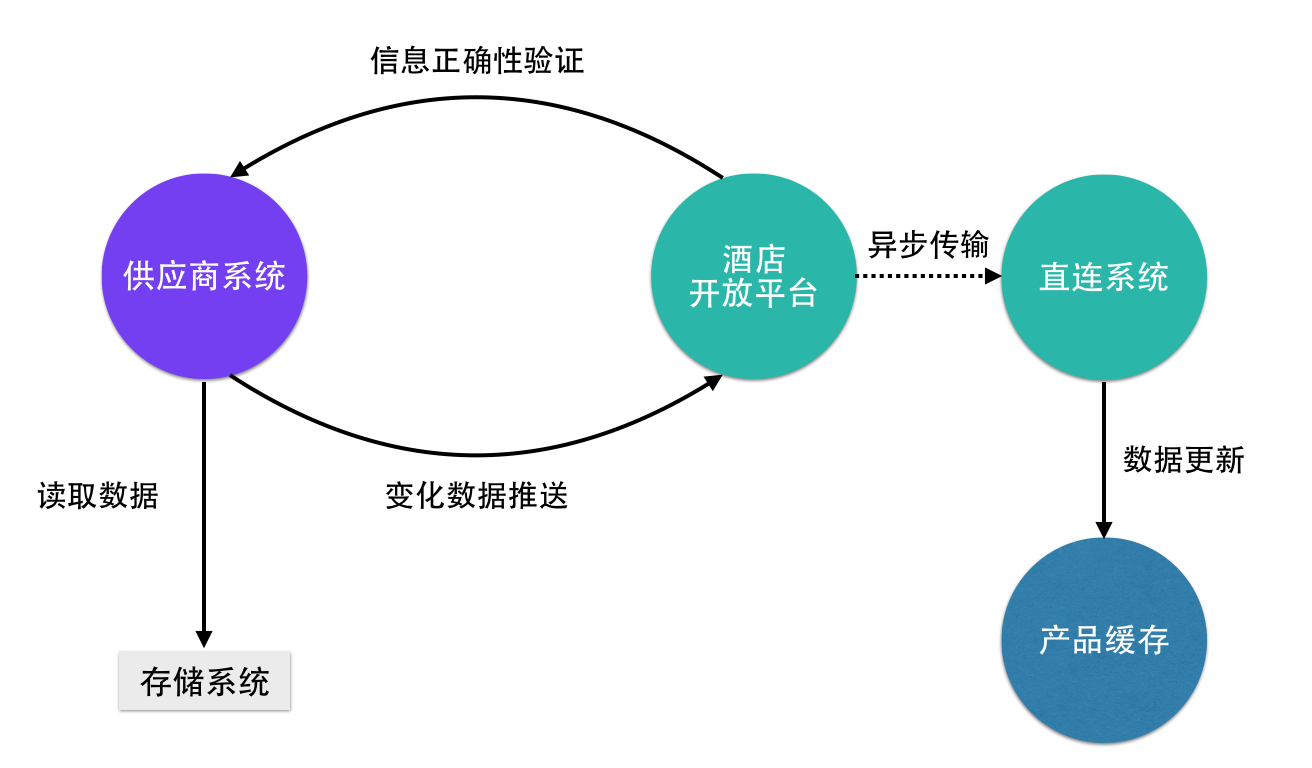
主动推送数数据其优势表现在:
- 减少服务访问次数,降低服务压力,服务更加稳定。
- 预订成功率上升,订单增多,收益也就增多。
酒店开放平台在适宜的时候开始提供标准API,部分有技术能力的供应商开始进行接入。
接入前为供应商提供统一的网站入口,提供接入文档,在线测试工具,常见问题答疑,在线问题解答等多方面的接入支持。
接入后提供数据分析平台,对接入数据实时进行统计。
采取以上措施之后,供应商对接入更加可控,线上产品运营情况更加透明。这样一来,供应商的接入意愿就有了极大的提升。
演化后的流程为: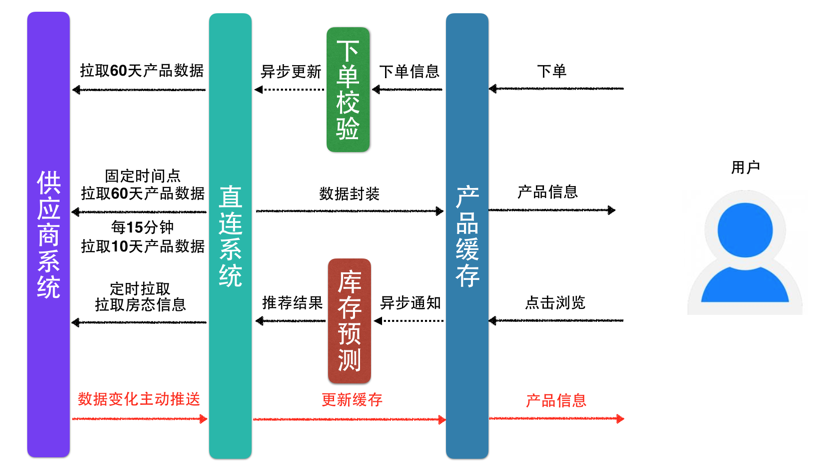
通过对获取产品数据功能的持续改造,使得直连系统为用户提供了可靠的数据来源。
总结一下上述四个阶段使用的数据的更新方式,分别为:
- 触发式
- 被动拉取
- 主动推送
直连数据一致性问题改造后,直连数据同步的架构如下所示: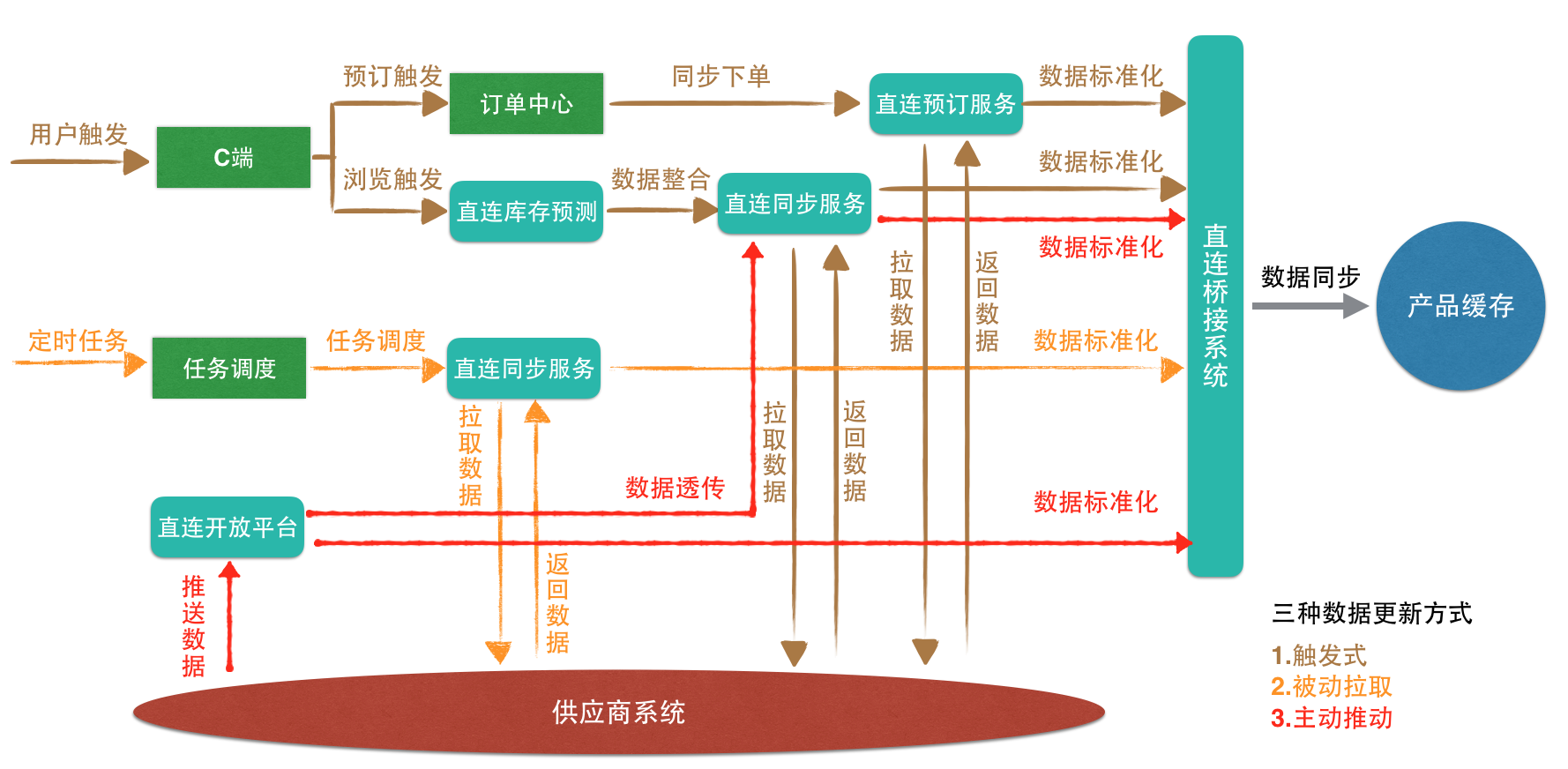
数据一致性的问题是O2O行业中最常见的问题,掌握一套有效的解决方案对项目建设,尤其是系统对接类的项目建设尤为重要。这里为大家介绍的是美团酒店直连平台应对此类问题时的具体实践。其中,随着项目规模变化而采取不同的应对方法是我认为最值得借鉴的地方。四个阶段的论述之前我分别对应用前提、方案优点、方案缺点加以说明,旨在让大家更有针对性的比对,结合自身系统现状予以应用。接着通过美团酒店直连平台的案例进行分析,从而方便大家更直观的理解。
美团酒店直连平台的成长是个充满挑战的过程,通过钻研和磨砺,平台的健壮性和运行效率显著提升。受篇幅的限制,很多细节无法详尽描述,数据一致性问题的解决也绝非一篇博文就能面面俱到,好的方案还需因地制宜才能充分发挥效用。上述供应商技术能力不足的问题,可以通过对方案灵活组合运用来解决。而对于此类相关的疑问,欢迎各位留言共同探讨。
技术平台的建设和维护,是个道阻且长的过程,数据一致性的问题仅仅是沧海一粟。希望这篇博文在数据一致性问题上可以为大家提供一些思路和借鉴。
- CSDN博客,《MySQL主从备份及原理分析》,2012.
- CSDN博客,《推荐算法之基于物品的协同过滤算法》,2014.
- 大数据杂谈,《推荐系统实践与优化》,2016.
- 大数据杂谈,《用一个大家都懂的方式来聊聊YouTube基于深度神经网络的推荐系统》,2016.
- 百度百科,推荐系统.
不想错过技术博客更新?想给文章评论、和作者互动?第一时间获取技术沙龙信息?
请关注我们的官方微信公众号“美团点评技术团队”。
这个API系统的本身目的是解决大量并发关系数据库查询的问题,主体设计思路是对PG中的表数据通过LRU等缓存算法缓存其中的数据,并进行请求合并也就是请求削峰服务,从而大量减少直连数据库操作,减轻数据库的压力,查询效率也大大提高。由于这个项目第一版各种指标要求不是很高,接着就面临一系列严重的问题:包括无法承载百万终端级别的数据;请求压力过大请求失败;内存和CPU在请求高峰时打满;出现goruntine崩溃和map读写冲突问题;性能和预期差的很远。独自接下优化这个项目后不得不一点dian回归重构,期间也就遇到了很多坑。。。
此次优化更多的是算法和Go使用技巧和特性的优化,包括简化递归算法的设计加速启动数据加载,数据结构的精简,缓存以及数据的复用共享减少内存压力,内存和CPU暴增的排查,定位和解决,GC与内存分配的优化,channel的使用坑,计时器的使用误区等等。对其中重要的我将通过几个真实的场景问题来介绍。
场景:API系统开启后需要快速的将100W终端的详细信息以及它们组成的大约1-10W不等分组信息从数据库中加载出来,但是速度特别慢100W数据需要大概1分钟以上,10W分组需要二十多分钟才能完全load下来。
100W的数据想要一条SQL查询下来并缓存肯定会出现不可预期的问题,数据量太大,这样搞最后肯定会卡死。所以采用切分策略,每次只取2000条左右,大概要取500次,ok,这没问题。问题出在如何切分以及下次从哪里开始查询,原先代码如下:
var minId int
ShovelSize = 2000
if err := Pg.Get(&minId, "SELECT MIN(id) FROM client"); err != nil {
return err
}
// 得到最小的id
lastSyncedID := minId
for {
var thisQueryResultCount = 0
// 然后查询id>lastSyncedID的数据
rows, err := Pg.Queryx(fmt.Sprintf(`SELECT id,mid,gid
FROM client WHERE id >=%d ORDER BY id ASC LIMIT %d;
`, lastSyncedID, ShovelSize))
/.https://www.zhihu.com/topic/
// 每次lastSyncedID+2000
lastSyncedID += ShovelSize
for rows.Next() {
thisQueryResultCount++
...
err = rows.StructScan(&c)
api.clientMgr.ReplaceInto(&c)
// lastSyncedID=c.Id +1
}
if thisQueryResultCount == 0 {
break
}
}
从上面的代码可以看出问题所在,当这100W数据id是连续的,每次取2000条然后每次lastSyncedID加2000没问题,一旦出现断了的id,就会出现重复的查询,而插入缓存的代码还要判断是否目前存在了该信息,存在了还要覆盖或者删除再添加,只要出现一个id中断要重复500次左右,出现100个中断将重复50000次的删除写入操作。所以需要修改两个地方,一个是lastSyncedID=c.Id +1,即随着每次查询更新最后面的id,不再盲目的直接增加2000,这样我们保证了每次查出来的信息都是与之前没有重复的,另一个是将Replace直接用Add替换,因为可以放心的直接插入不用再像之前那样判断很多项是否存在,然后再插入。这样100W的终端数据缓存速度在几秒钟就完成啦。
场景:影响初始化速度的另一个因素是每次加入一条分组信息要回归所有的子分组和父分组的children信息,更新数据,10W条分组要递归10W次,导致10W数据要20+分钟才能加载完。通过gid获取该分组的所有子孙分组以及从顶层到该层的分组路径,当查询gid=1时需要60s+,如何优化?并且一旦有一个分组的信息改变可能需要递归所有相关的分组缓存信息,如何做到?
递归算法是一种直接或者间接调用自身函数或者方法的算法。实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解。递归是一门伟大的艺术,使得程序的正确性更容易确认,而不需要牺牲性能,但这需要我们能将复杂的问题抽象出最简单的数据模型来实现,使用不当不仅效率大大下降,有时候还会出现意外的崩溃。之前刷ACM题的时候就和同学经常说大部分的算法题都可以用二叉树和递归解决,真实场景确实也如此。
10W分组的数据,每个分组带有分组的id以及父分组的id,还有分组信息的更新时间等一些信息,程序原先的方法是缓存下来所有的分组信息,并一一计算它所有的children的id,一旦有一个分组出现修改要回滚计算所有的children分组和父分组,计算量还是非常大的,试想分组id如果是1,将重新递归计算10W分组信息。但我分析了下数据特征发现这些复杂数据的递归本质上是不必要的。
原始代码片段:
groupTbl map[int]*RawGroupinfo
type GroupCalcResult struct {
Children []int
Path []int
OutputJson []byte
}
func getAllchildrenbyid(id int, children []int, recursiveChildrenNum int, maxRecursive int) ([]int, int) {
isEnd := 0
recursiveChildrenNum++
if recursiveChildrenNum <= (maxRecursive + 1) {
allFirstInfo := gm.groupTbl
for childrenkey, childrenvalue := range allFirstInfo {
if childrenvalue.Pid == id {
children = append(children, childrenkey)
children, isEnd = getAllchildrenbyid(childrenkey, children, recursiveChildrenNum, maxRecursive)
}
}
} else {
isEnd = 1
}
return children, isEnd
}
可以看到这个递归使用上没有什么问题,在数据量不大的情况下问题同样可以解决,但是我们可以看出一点,就是关注的信息太多,返回值太多,而这些值对于我们问题本身并没有什么必要用处,我们关注的就是id之间的父子关系,并且递归过程还出现了map读写冲突的bug,而这些读写是不必要的,也不是我们问题的关键。最初我以为是递归算法本身的问题,我照着上面的结构撸了个多叉树期望在算法效率上解决这个问题,经过测试我发现关注的信息太多并没有明显的优势。经过仔细分析,其实我们关注的无非就是int型的id以及id之间的上下级关系嘛。我们抽象下这个数据结构,10W分组的数据,结构如下:
1:[2,3,4,5,6,7,8,9]
2:[11,12,13,14,15,16,...]
11:[110,111,112...]
....
首先,我们不能时时刻刻维护这一个数组来保存着子子孙孙,只需要关注自己的儿子,不然怎么管的过来,还有就是对于没用的每个分组的附加信息在我们的关系结构中根本不需要,试想我们知道一个人和自己的关系,还需要带上他穿多少衣服,今天吃了什么吗?两个数据结构就可以维护我们的分组信息,10W的分组详细信息:map[gid]GidInfo和分组的父子信息map[id][]int。优化后
// 某个组id的children查询
func childrenSearch(groupFamily map[int][]int, data []int) []int {
res := make([]int, 0)
for _, v := range data {
res = append(res, v)
res = append(res, childrenSearch(groupFamily, groupFamily[v])...)
}
return res
}
经过测试后, 10W分组的id查询时间从之前的60s+变成了0.1s左右。
场景:通过gid获取全部的终端信息,请求查询gid=1时返回数据大概32Mb,上百并发时16G内存的服务器一下子占用了其中的12G+,如何降低?
一个请求的返回数据32M,当同时有上百个这样的请求发起时内存暴增12G,当时的我是崩溃的,一遍遍的过代码,看pprof的内存数据,始终没有发现内存泄漏的问题,后来才发现,这个问题其实不是我看到的问题表面原因或者说问题是为何内存长时间占用不释放,并发请求过来内存暴增其实是正常的,因为毕竟一个请求就32M,好几百个请求同时过来不暴增才怪。
这里其实是Golang内存分配认识的一个坑:为了保证程序内内存的连续,Golang会申请一大块内存(甚至只写一个hello, world可能都会占用100M+内存)。当用户的程序申请的内存大于之前预申请的内存时,runtime会进行一次GC,并且将GC的阈值翻倍。也就是说,之前是超过4M时进行GC,那么下一次GC就是超过8M才进行。我们内存暴增的原因,就是访问量过大导致内存申请,并且GC阈值也一下子变大,回收频率变低,同时GC还预测以后可能还会需要这块大内存为了优化内存分配就一直不释放给系统啦。而且Golang采用了一种拖延症策略,即使是被释放的内存,runtime也不会立刻把内存还给系统,而是在自己不需要并且系统需要的情况下才回还给系统。这就导致了内存降不下来,一种内存泄漏的假象。所以难怪我一直找不到内存泄漏原因。
找到原因之后,解决方案是定时将不需要的内存还给操作系统,debug.FreeOSMemory(),不过这个请慎用,最好不用,最好的解决方案是:
场景:在系统刚调试完成,请求正确处理的那一刻内心是激动的,然后当服务开启之后,习惯性的查看了下功耗,内存使用正常,CPU却在眼下不断增高,2%-5%-10%-20%-50%-80%-100%,在短短几分钟就飙到了100%。。。内心是崩溃的,此时刚从一堆代码中缕顺流程。如何快速的定位到问题?我应该从哪些方面下手,或者说我应该查看哪些数据来推测所有的可能性?究竟是哪个package,哪个函数甚至是哪一行代码影响了它的性能?这里主要说明排查定位过程。
开启pprof接口查看运行时cpu数据和heap数据。
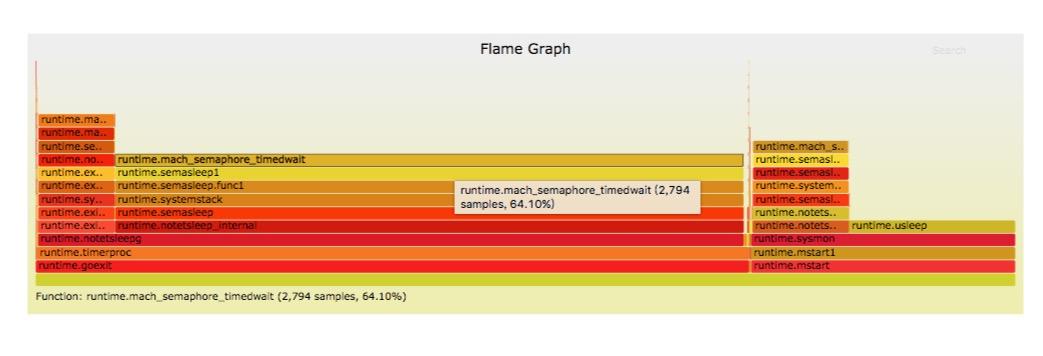
从火焰图我们可以很方便的分析各个方法占用的CPU的时间。 它是SVG格式的,鼠标放上去还能看细节。Y轴是栈的深度,X轴是所有的采样点的集合,每个方框代表一个栈帧(stack frame)。 颜色没有意义,只是随机的选取的。左右顺序也不重要。看的时候可以从最宽的帧看起,从底往上看,帧上的分叉代表不同的代码路径。快速识别和量化的CPU使用率
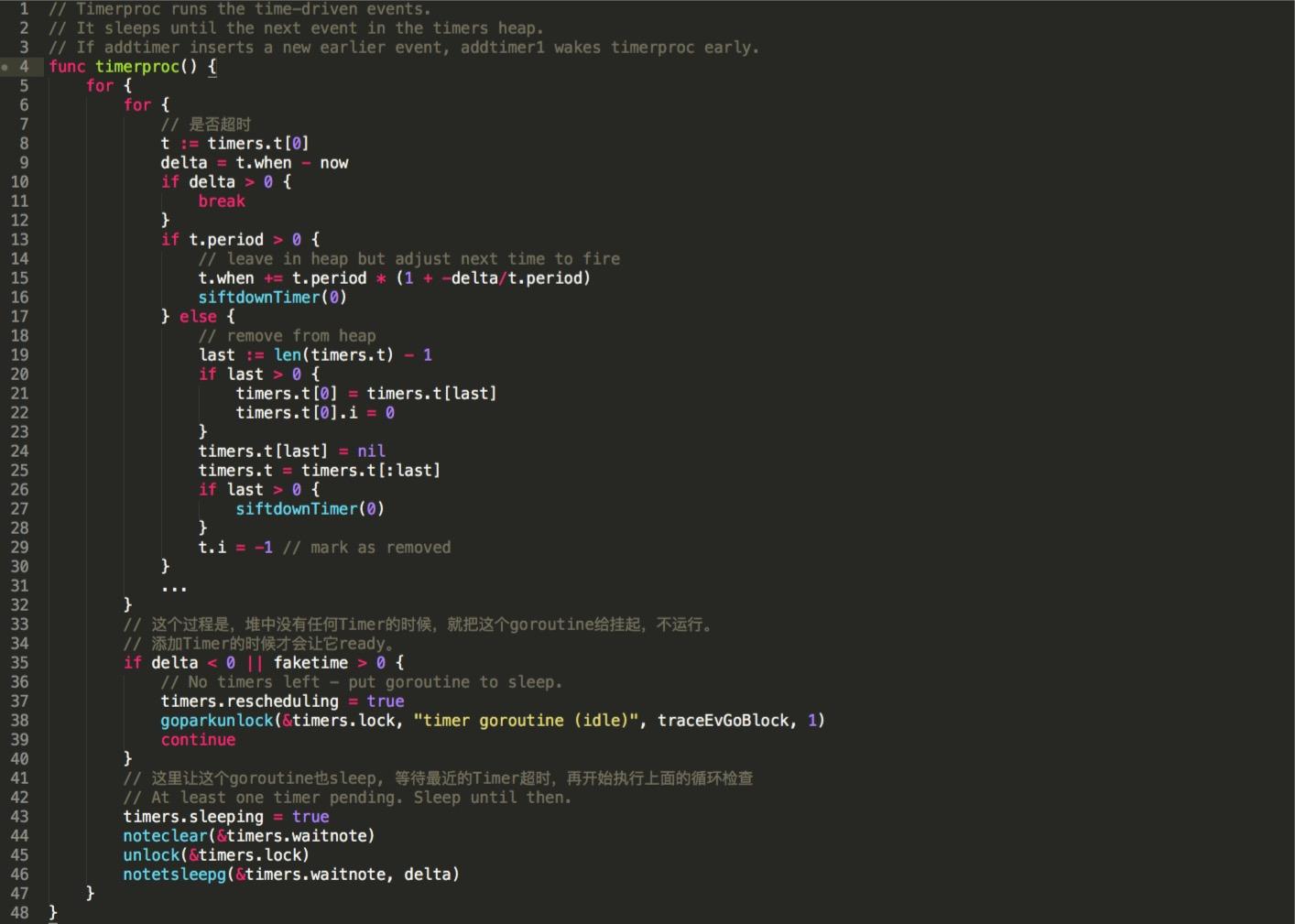
从火焰图的信息可以看到,在整个cpu占用信息采集过程中几乎全部都是runtime的信息,并且是runtime.timerproc。通过分析go语言的源码我们可以知道这是一个定时器调度goruntine。(代码是go1.7.3源码,我经过了裁剪,保留大意)
从火焰图往上或者我们从pprof的cpu走向来分析(如下图)看就可以看到我们上面提到的runtime.mach_semaphore_timewait。所以在此我们可以推断,根源就在定时器的使用,那么全代码搜索所有使用time包方法的代码。发现是和time.Tick()和time.After()两个函数相关。那么问题就出在这里啦。
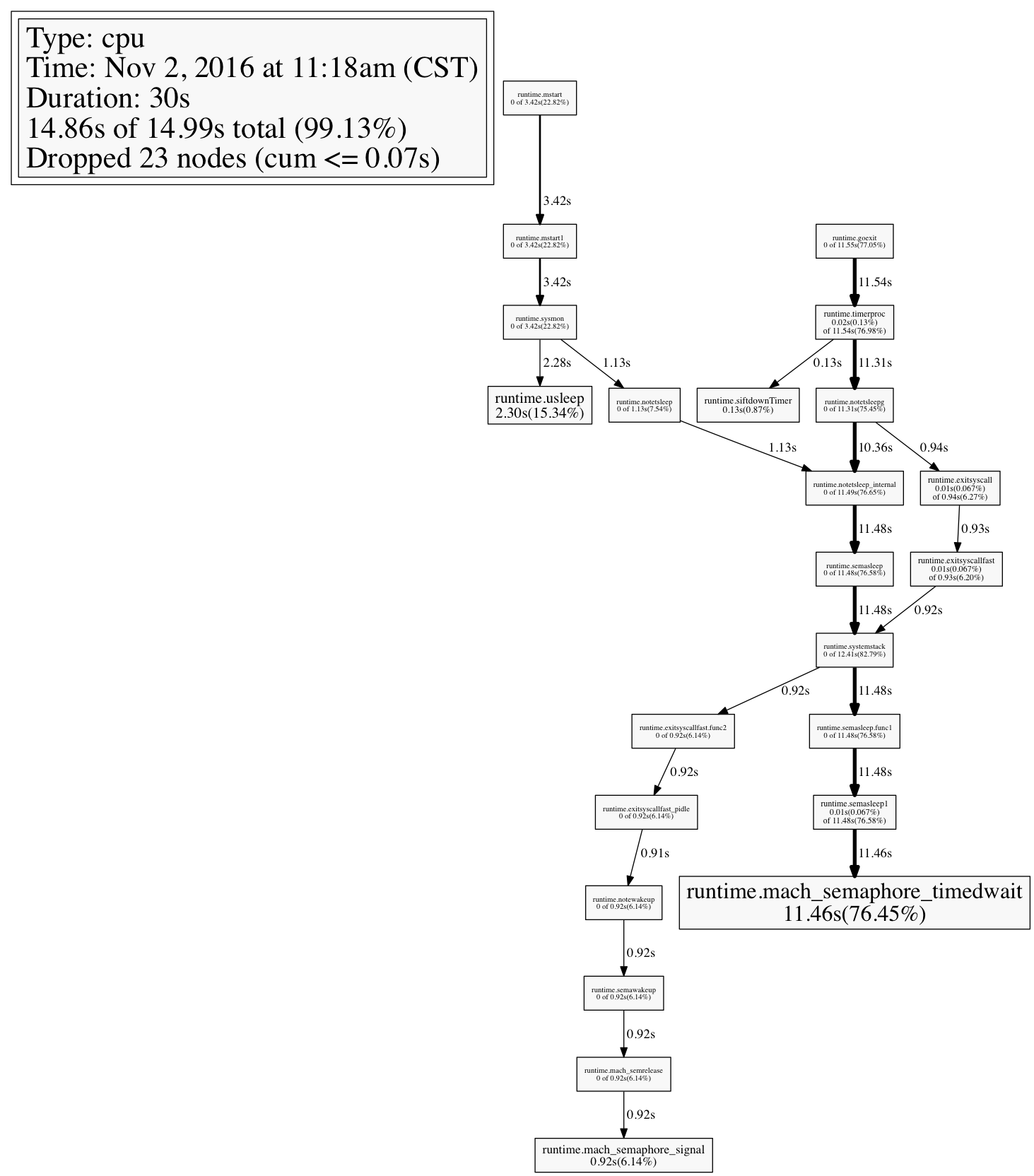
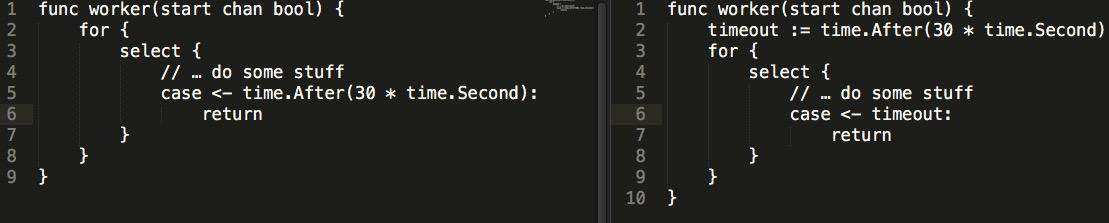
上面这两个例子,单独执行,不会发现任何问题,但是当你将这样的代码放到一个7 * 24小时的Service中,并且timeout间隔为更短时间,比如0.1s时,问题就出现了。
最初我怀疑是不是代码中有死循环,但仔细巡查一遍代码后,没有发现死循环的痕迹,算法逻辑也没问题。于是重启了一下这个service,发现cpu占用降了下来。继续用top观察,不好,这个service占用了1%的CPU一直上升,观察一段时间后,发现这个service对cpu的占用率随着时间的推移而增加。
从火焰图上可以看出几乎都是timeproc goroutine的调度。回到代码,发现可能存在问题的只有这里的tick和after。
回到我们的代码,timerproc指针维护的是一个goroutine,这个goroutine的主要功能就是检查小顶堆中的Timer是否超时。当然,超时就是删除Timer,并且执行Timer对应的动作。我的Timer间隔是1s。这样每1s都会创建一个runtime timer,而通过runtime的源码来看,这些timer都扔给了runtime调度(一个heap)。时间长了,就会有超多的timer需要 runtime调度,不耗CPU才怪。
找到原因之后,继续分析了造成timer过多的原因,一个是配置项中的时间间隔太小(0.1s)一个是上面看到的代码逻辑bug,两者一起造成了CPU飙升.修复代码中存在的bug,调节参数间隔大小.CPU立马降了下来。
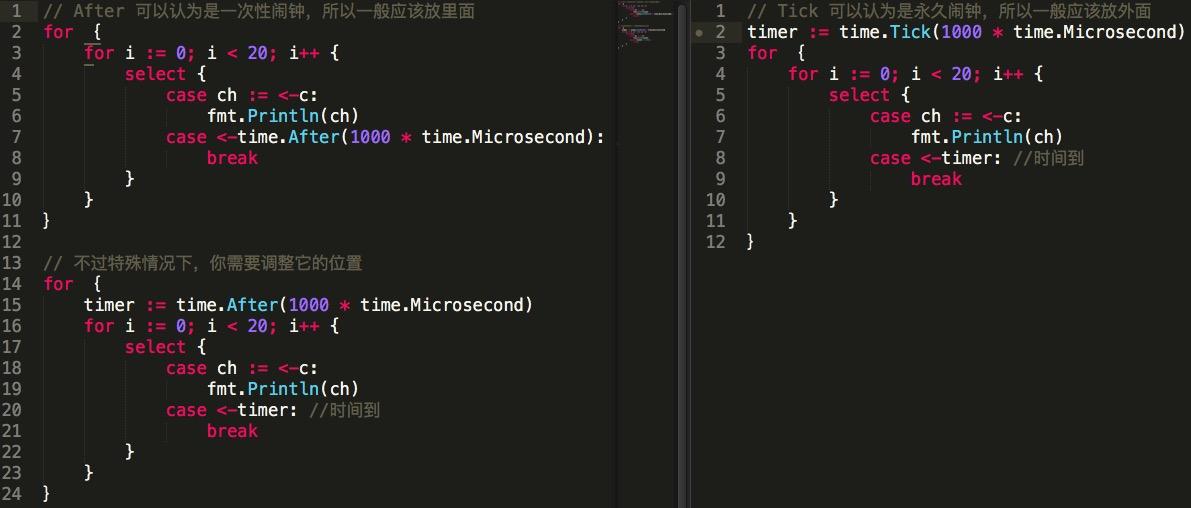
那么问题来了我们应该如何正确使用定时器呢?
场景:这是客户那里发现的一个很深的bug,说它深是,这个bug会在正常启动程序后,接收到请求后中断数据库才可以触发。
之前写C/C++时经常坚守的一个规则是在使用数组时,如果要遍历要首先获取到数组的长度,然后再去遍历它,而不是直接在for循环中求长度,因为一旦数组有变化会导致不可预期的bug,但通常直接写在循环中是可以的,所以很多人会习惯这个写法。一般的程序还好,但是在golang中最好不要这样,因为在并发中这样写非常容易出错,例如:
if subChain, ok := psgrRegister[strings.Join(psgr, `-`)]; ok {
// 此处应该注意不能直接在循环里面使用len(),因为一旦close一个chan这个数字就变了,会导致严重bug
BROADCASTLOOP:
for i := 0; i < len(subChain); i++ {
select {
case waiter := <-subChain:
waiter <- msg
close(waiter) // 一旦close chan的长度会减少1
default:
break BROADCASTLOOP
}
}
close(subChain)
}
可以看到每当close一个chan原先的chan数组元素个数就减少了1,所以在并发请求过来后发现最后的几个请求结果是null,就是因为在这里提前结束了。
场景:在给某银行60W终端压力测试过程中,出现内存占用暴增的情况,原因是API缓存系统一个重要功能就是监控数据库状态并及时同步数据变更,我们采用的触发器的形式通知API系统,压力测试时,频繁的改动和表变更导致开启了大量goruntine处理数据,高峰时堆积达到几百万个
这个原因是两个方面,一个是我们的数据处理很慢,大概可以达到每秒几十个的样子,后来经过我优化提升了十倍左右能每秒处理上百个但没有解决根本问题,另一个重要问题是设计上的问题,也就是我们两个业务共用了一个触发器,但其中一个只对表中的四五个字段感兴趣,其他修改不修改无所谓,但我们没有分开,导致大量变更触发,而我们这部分逻辑的处理性能达不到,导致了这个问题。这个问题在刚接手这个项目时考虑到了这个潜在问题,但当时一直没有问题,索性没有理会它,成功的验证了墨菲定律。
其他就是一些零碎的知识点了,例如map在并发读写时一定加锁,slice大小初始化有根据,channel不要忘记close等等。
从系统优化的这些问题可以看出:
作为一个电脑系统爱好者,Yixue最不能忍受的事情就是:PC速赶不上脑速!
谁都无法忍受慢吞吞的电脑,它极大地消耗了我们对工作和做事情的热情。无论你的PC是继续启动还是继续冷冻,都不要使用慢速PC,你可以尝试着做几件事情来加速你的计算机运行速度。

以下操作皆基于win10操作系统~
1.任务管理器会是你的好朋友
任务管理器提供了有关计算机性能的信息,并显示了计算机上所运行的程序和进程的详细信息。任务管理器可以帮助你深入地了解处理器负担、占用的内存量、以及程序使用的网络数据量。
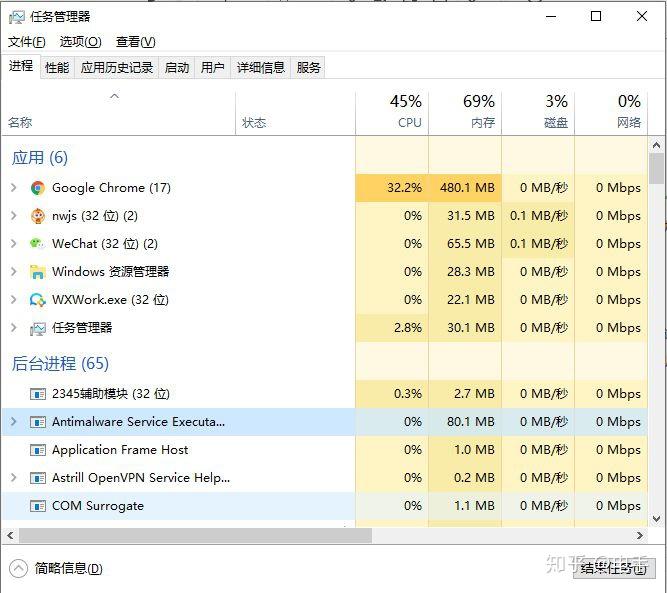
默认情况下,列表分为应用程序和后台进程,它们每分每秒都在不停地更新,建议可以观察几分钟,查找高内存或者CPU使用率高的进程,选择你认为降低性能的进程,点击“结束任务”进行关闭。
打开任务管理器的方法也特别简单,Yixue知道的主要有下面三种:
- 右击任务栏任一地方,选择“任务管理器”菜单。
- 按快捷键“Ctrl+Shift+Esc”或者“Ctrl+Alt+Del”。
- 按下快捷键“win+R”,打开“运行”面板,输入“taskmgr”命令,也可以调出任务管理器。
2.禁用不需要的启动运行程序
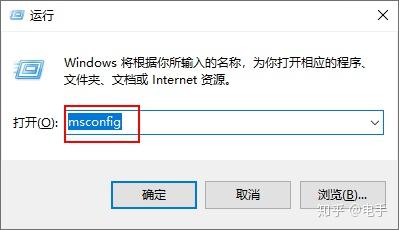
按下快捷键“Win+R”,输入“msconfig”,通过禁用不需要的系统服务来加快你的PC运行速度,启动运行太多也会拖慢速度。
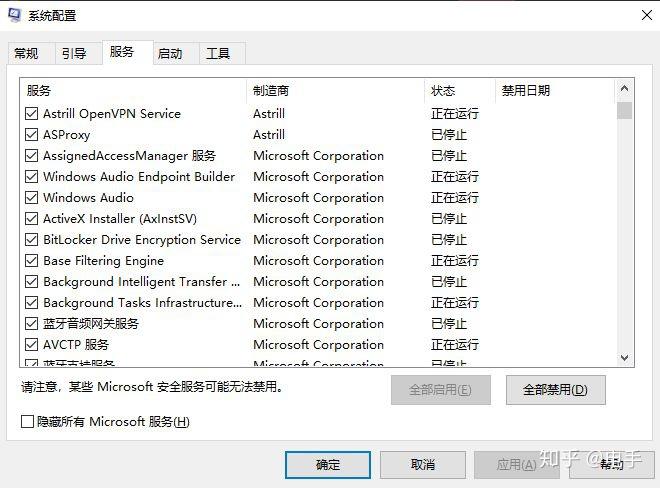
在系统配置中,禁用你不需要的服务项,这里也可以通过“启动”选项卡进入任务管理器的“启动”项。
3.定期进行磁盘清理
PC用久了之后会产生很多无用的垃圾文件,这些文件有时候在一定程度上也会占用我们PC的内存,拖慢运行速度。你需要的是定期进行磁盘清理。
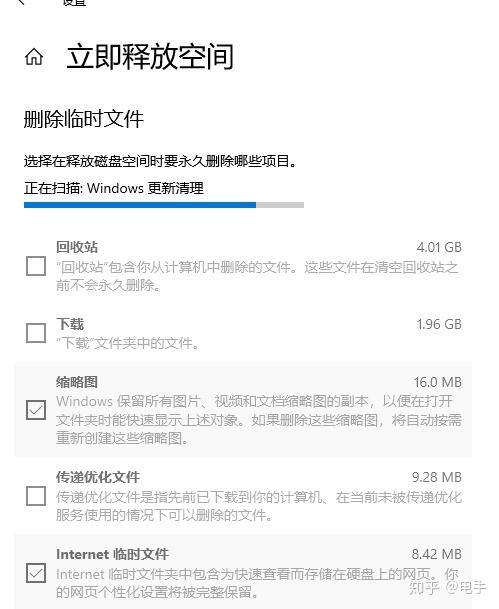
- 右击系统盘C盘,选择“属性”命令,选择“磁盘清理”。
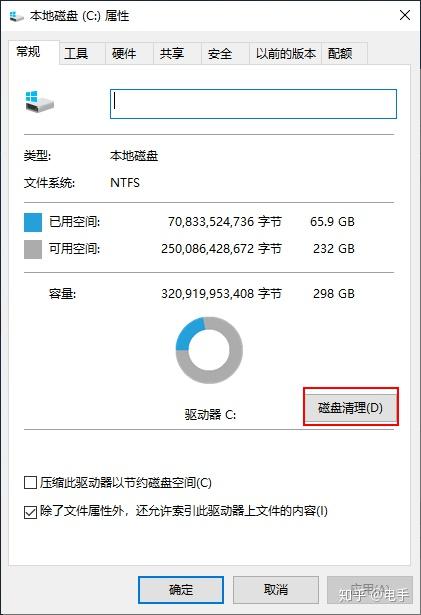
- 在弹出的“磁盘清理”对话框中,你可在滚动列表里面勾选你需要清理的文件,也可以清理“系统文件”。
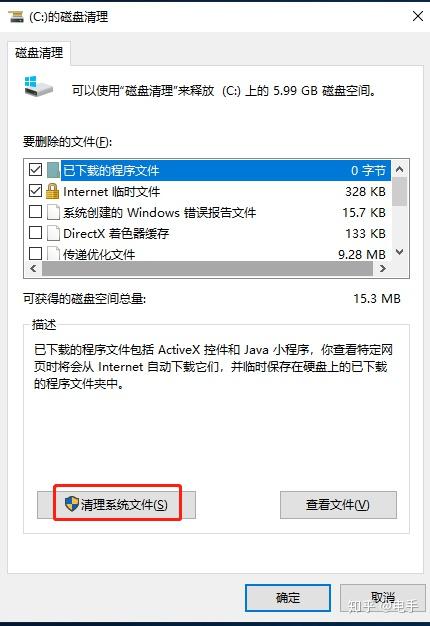
- 进行这些操作一般都要重启系统才会生效,所以Yixue建议可以每天关闭电脑的时候进行一次磁盘清理。
- 磁盘碎片整理也可以提速哟。
4.关闭防病毒扫描
之前Yixue进入电脑的时候,经常可以看到防毒扫描程序位于桌面某处,防病毒软件可以在系统主动扫描您的计算机以查找恶意软件和病毒时降低系统速度。时不时就会喊你修复各种系统漏洞,扫描清理各种盘,其实是越修复越卡。当然你可以在不使用PC的时候安排它进行扫描。
市面上这种防病毒软件很多,像国内360、瑞星、金山毒霸、电脑管家等,国外的诺顿、卡巴斯基、Nod、大蜘蛛等都是耳熟能详的软件。值得一提的就是杀毒软件一般只安装一个就够了,安装多了容易占用资源,还容易“相爱相杀”。

以前,Yixue的电脑上同时安装了360和电脑管家,这两货时不时就会“打架”,经常产生冲突导致系统异常,我算是体会到“酸爽”的痛楚了。
5.卸载你不常用的应用程序
对于一些经常不用的应用程序留着也会占用系统资源,你可以进入控制面板找到程序进行卸载,减轻PC的负载。
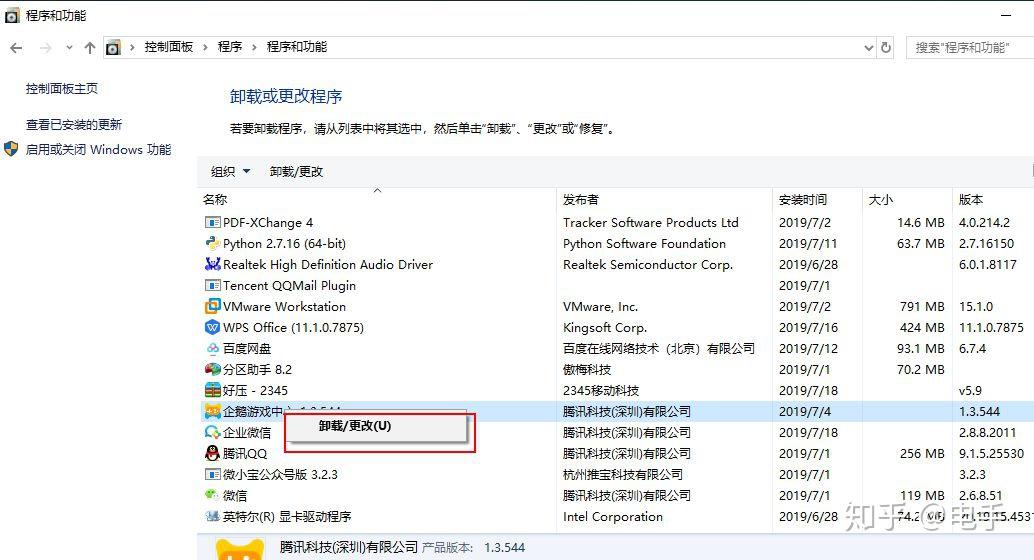
控制面板的入口除了在开始菜单中进入,大家也知道在“运行”面板里面输入“control”也可以进入。
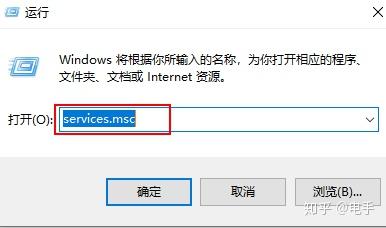
6.关闭系统自动更新
关闭系统自动更新可以很大程度上加快速度和释放内存空间。
- 使用“Win+R”快捷键调出运行面板,输入入“services.msc”,打开本地服务管理。
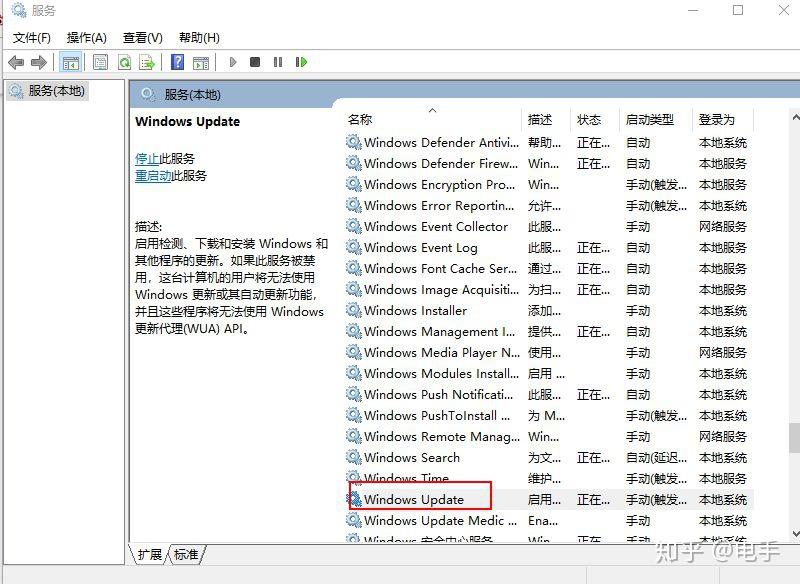
- 在选项中找到“Windows Update”选项,右键快捷菜单单击“停止”则可以 关闭系统自动更新。
7.浏览器超载
我们在使用浏览器的时候总是习惯窗口多开,其实每个窗口和选项卡都会占用内存和处理能力,当你完成某项操作的时候最好关闭某个窗口或者应用程序,这样也便于工作和观看。并确保它们未在通知托盘中运行(在卷和Wi-Fi指示符旁边)。当您关闭某些应用程序(如Slack)时,它们会继续在后台运行。
8.关闭开机启动项
开机启动项目太多的时候也会大大拖慢你的PC运行速度,我们可以设置取消一些不必要开机启动的项目,优化电脑的运行性能。以下为win10版本操作操作:
- 只需要右键“开始”菜单选择“应用和功能”命令或者“设置”都可以调出开机启动项。关闭一些不需要开机启动的程序即可。
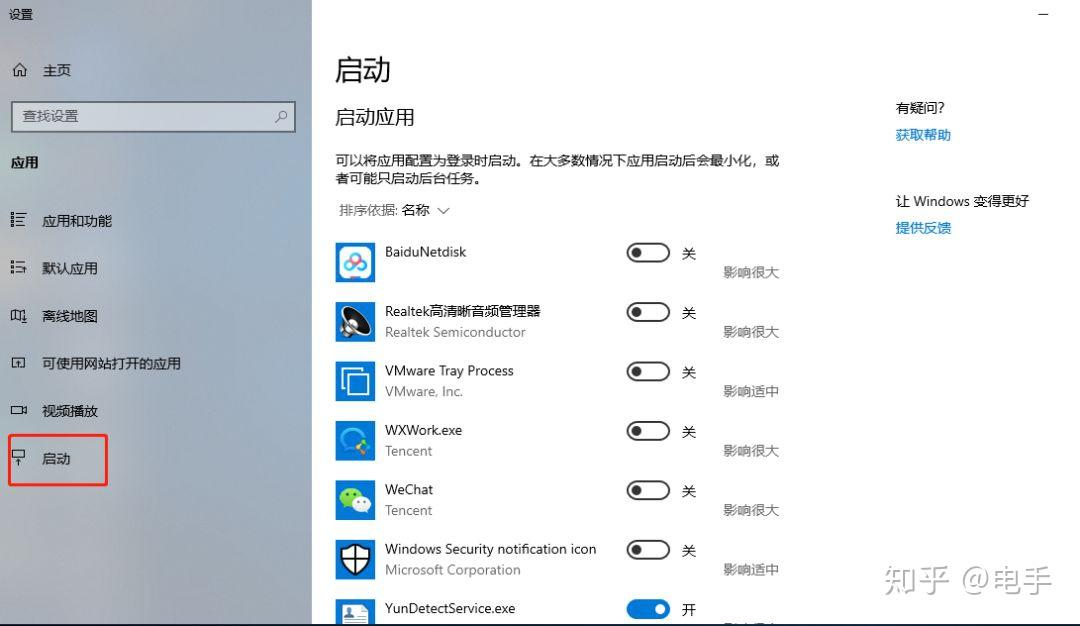
如果某些系统版本没有这个“启动”项,可以进入任务管理器的“启动”进行设置。
9.利用win10原生功能,一键快捷清理内存
不用下载任何软件,不用进入控制面板或者系统设置,win10这个原生功能我不知道有多少人用过?
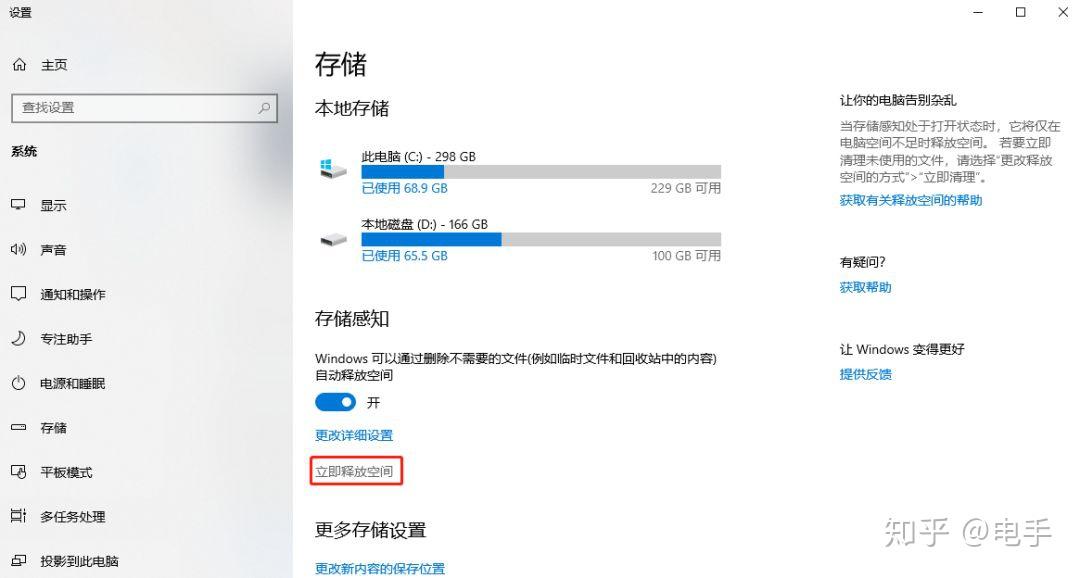
- 在win搜索框中搜索“存储”,打开“存储设置”。

- 在“存储设置”里面点击“立即释放空间”,系统即可快速扫描磁盘无用文件进行清理,是不是又方便又快捷?
10.增加SSD
SSD(固态硬盘)比机械硬盘的速度更快,我们都知道机械硬盘的读写速度是7200转,但是这远远不够的,固态硬盘的一个核心问题就是解决运行慢,当你安装上固态硬盘之后 ,你的PC速度就好像从泥泞的小路突然跑到了高速公路上,飞速运转。
优化软件和系统只能是锦上添花,增强硬件设备才是加速PC运行的关键。

上面的几种方式可以在一定程度上加速你的PC运行速度,但是最主要的还是看PC本身的配置,比如你的电脑运行内存只有4G、老掉牙的奔腾型号处理器,你又想玩多机游戏,还想多开应用程序加虚拟机,肯定是慢得不行。
对于一些对视频、图片处理有较高的要求的人,在选择PC上要考虑运行内存、显卡、处理器等多种因素。我想大多数专业人士都差不多是内存8G、处理器I5起吧?总之,适合自己工作需要的电脑配置+实时的系统软件优化,你的PC运转应该会趋于正常水平。
关于加速PC运行速度,大家还有别的看法吗?欢迎留言区盖楼。
Windows10重装系统后,打开蓝牙开关,电脑处于可以被发现的状态,但是添加蓝牙或其他设备时会显示无法连接,即无法主动连接其他设备,但可以被动连接。此时可以连接手机等设备,但是无法连接蓝牙耳机。


- 反复开关蓝牙及重启系统,无效
- 自动更新系统驱动,无效
- 在电脑品牌对应官网下载驱动并更新,无效
- 第三方软件更新驱动,无效
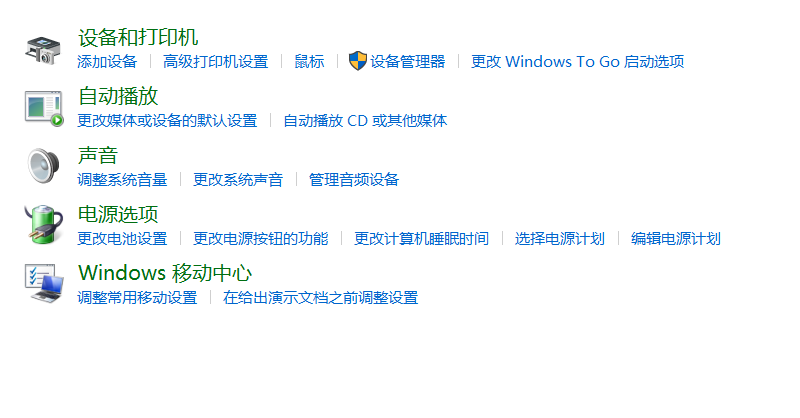
- 右击此电脑“管理——设备管理器”,禁用/卸载重装蓝牙设备,无效
控制面板——设备和打印机——添加设备,此时会自动搜索附近蓝牙设备,检测到蓝牙耳机会自动安装Nahimic音效软件,点击搜索到的蓝牙设备即可成功添加,但是如果在设置中直接添加依然无法成功。


从Windows10开始,微软在Windows中增加了大量遥测功能。用户会将数据发送给微软,微软会根据数据提供个性化推送、产品优化、问题诊断等服务。
然而,虽然微软一再承诺会保护用户隐私数据,并且有些数据还是匿名的,但是……
谁知道呢?
再说了,为啥非要浪费流量发送这些东西?
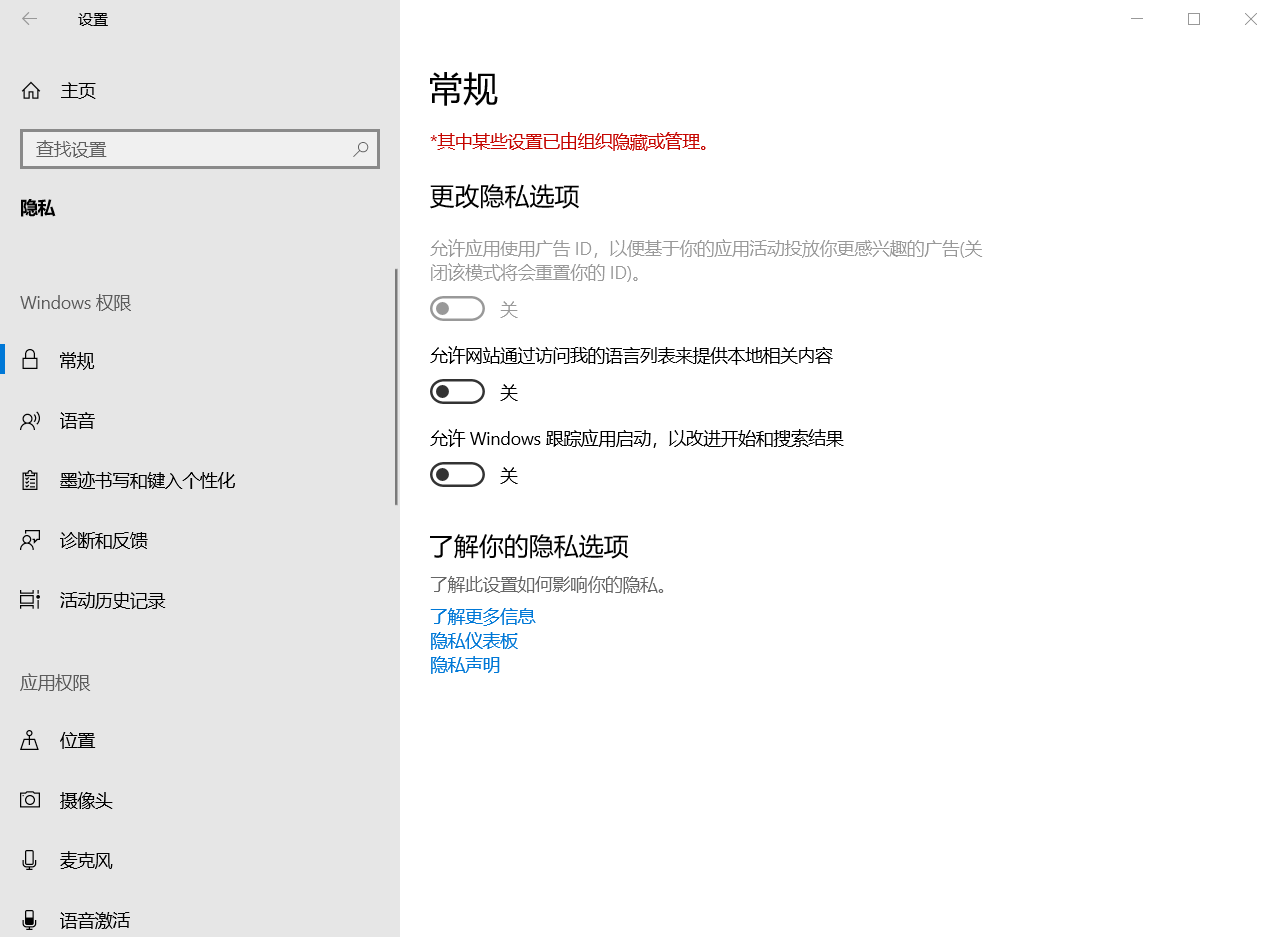
很可惜,按照微软的一贯德行,如果只是在设置中,我们无法彻底关闭遥测,这时候就要借助专业软件了。
Privacy dashboard for Windows,简称WPD,一款免费、绿色无广告的Windows隐私保护工具。
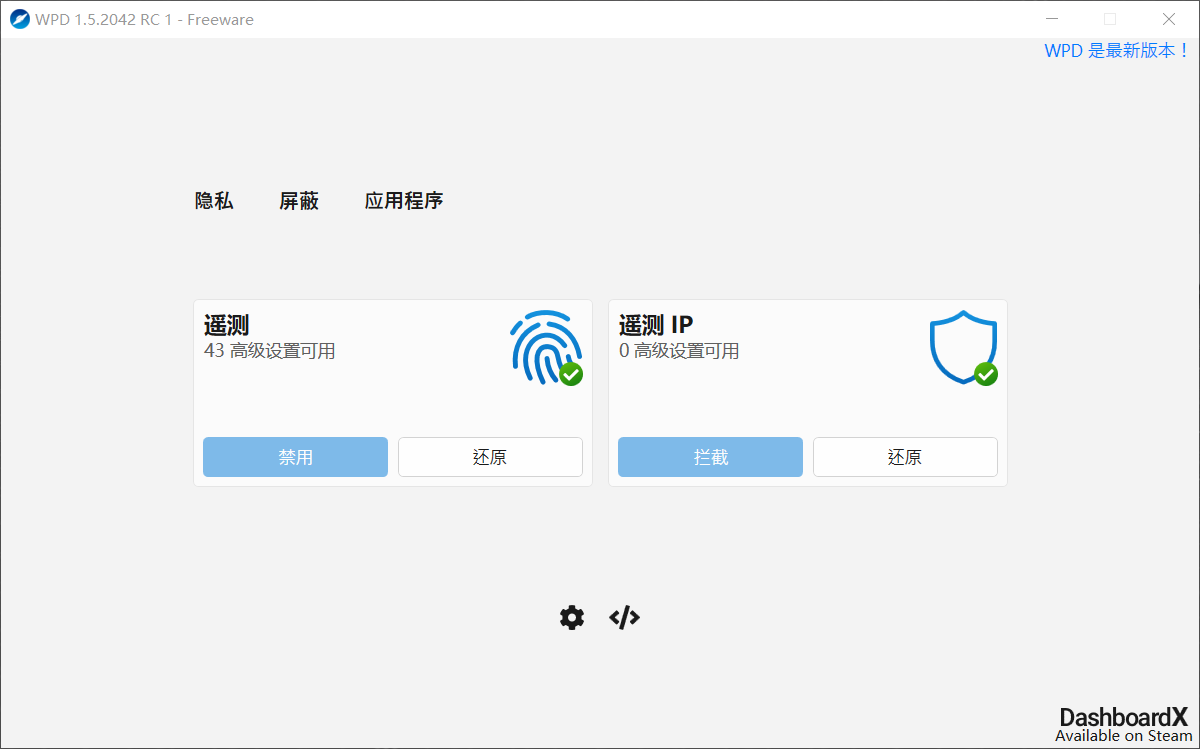
官网给出的软件介绍是这样的:
A small but powerful portable tool that works through the Windows API. WPD is the most convenient way to configure various privacy settings in Windows.
一个小而强大的可移植工具,通过 WindowsAPI 工作。WPD 是在 Windows 中配置各种隐私设置的最方便的方法。
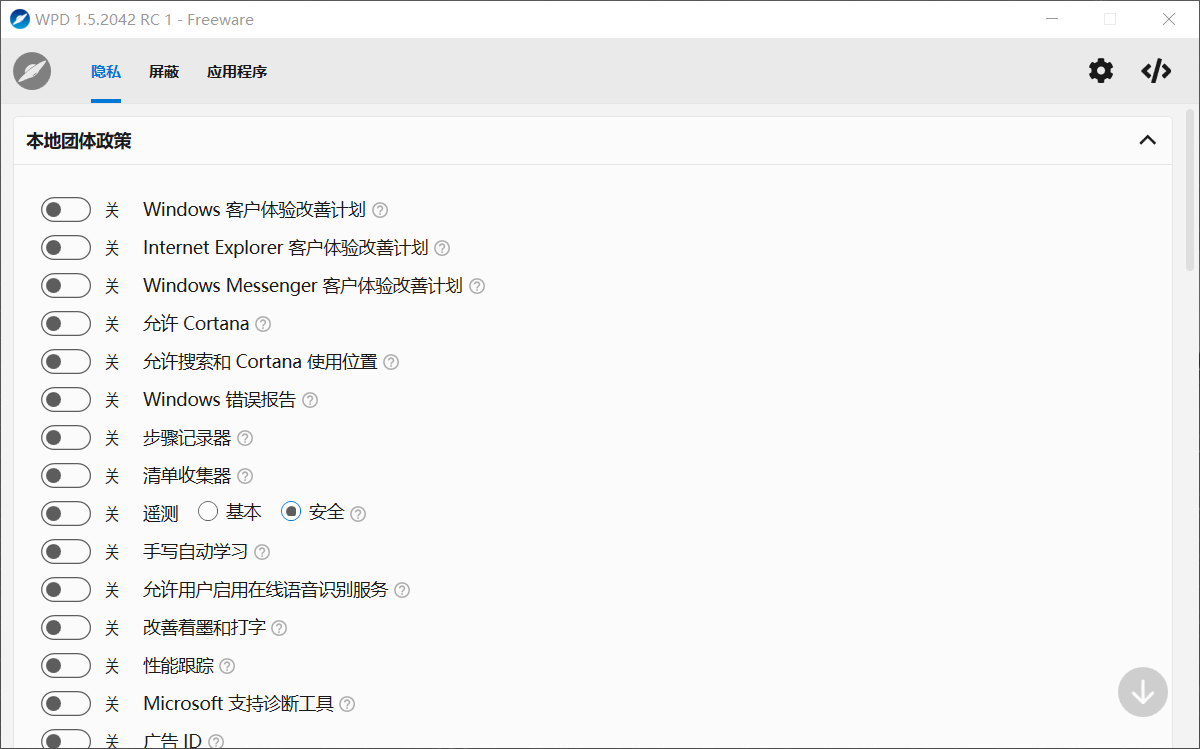
如果图省事,直接在主页点击禁用和拦截两个按钮即可,WPD可以自动通过修改注册表、禁用服务等方式阻止遥测。如果希望更加详细的设置,打开遥测还可以关闭具体项目,可以让我们更加明了地保护我们的隐私信息。
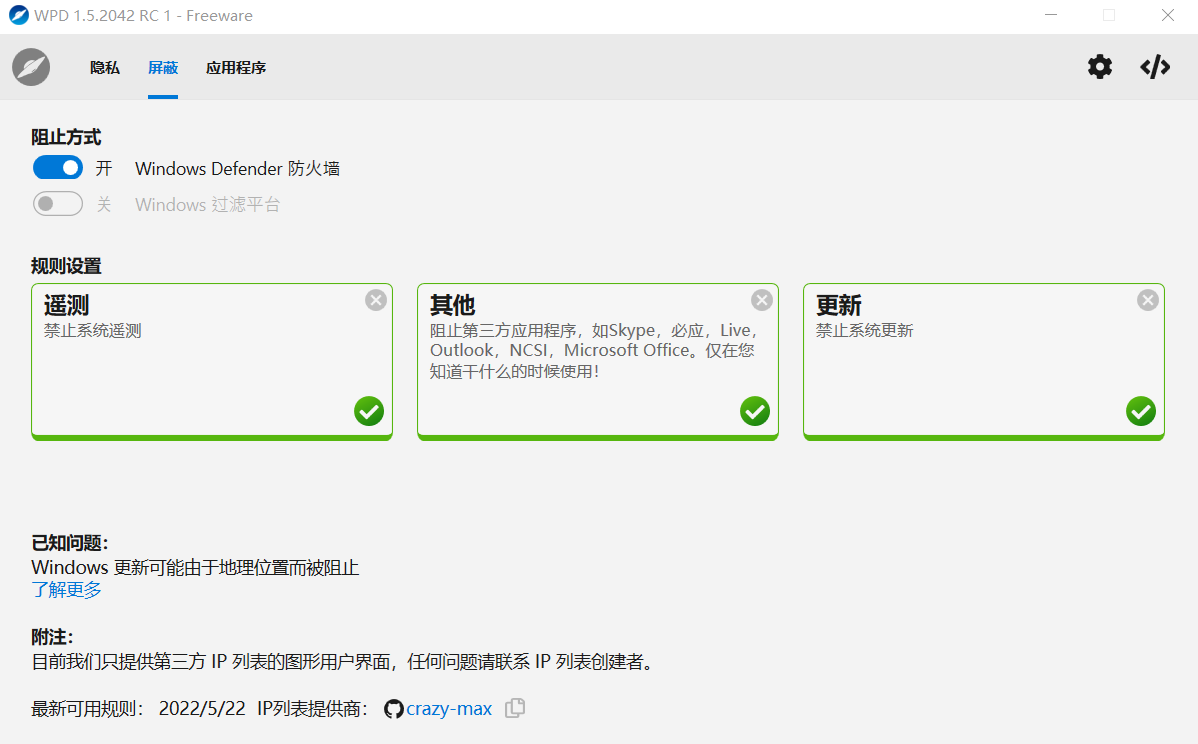
其中,最下方的Windows Update还可以一键关闭Windows自动更新,此时设置界面的自动更新会显示出现错误。相对于笔者曾经的文章Windows优化策略#1:彻底禁止Windows更新,操作更加简单。如果需要恢复更新(如启用或关闭Windows功能),在WPD中打开即可。

当然,在遥测IP中,我们还可以使用Windows防火墙来屏蔽对遥测反馈地址的访问,从而进一步保护隐私。
既然说到Windows更新,就不得不提到另一款快捷工具软件了——Windows Update Blockers。这也是一款免费软件,专门用于阻止Windows自动更新。只需要点击Disable Updates并点击Apply Now即可。为了防止Windows更新死灰复燃,还可以勾选上Protect Services Settings。
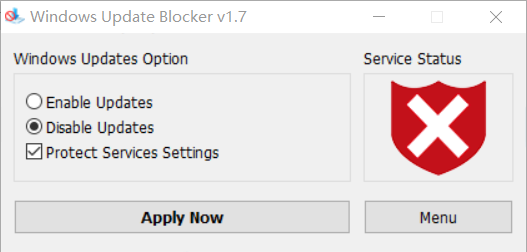
此时虽然Windows自动更新被禁止了,但控制面板中启用和关闭Windows功能不受影响。
两款软件均可通过官网免费下载。


